
こんにちは。CQO室 QAエンジニアのTodoです。
2025年12月3日に「マネーフォワード クラウド契約」から「リース識別エージェント」がリリースされました。
「リース識別エージェント」はワンストップ契約管理サービス『マネーフォワード クラウド契約』において提供するAIエージェントです。エージェントが電子化された契約書を解析し、リース取引となる該当性の一次判断、根拠条文や仕訳に必要な要素の抽出を行います。
このAIエージェントがユーザー課題を解決できるかを判断するために、客観的な立場のCQO室に精度評価が求められました。
そこで、AIプロダクトの品質保証の知識ゼロ、従来の機能テストQA経験のみの私が、このAIエージェントの精度検証を担当することになりました。これは、私にとって新しい挑戦でした。
本記事では、約3ヶ月の検証期間を通じてどのように模索してきたかをご紹介します。
想定読者
- AIエージェントの品質保証経験が無いQAエンジニア
AIエージェントの精度検証プロセス
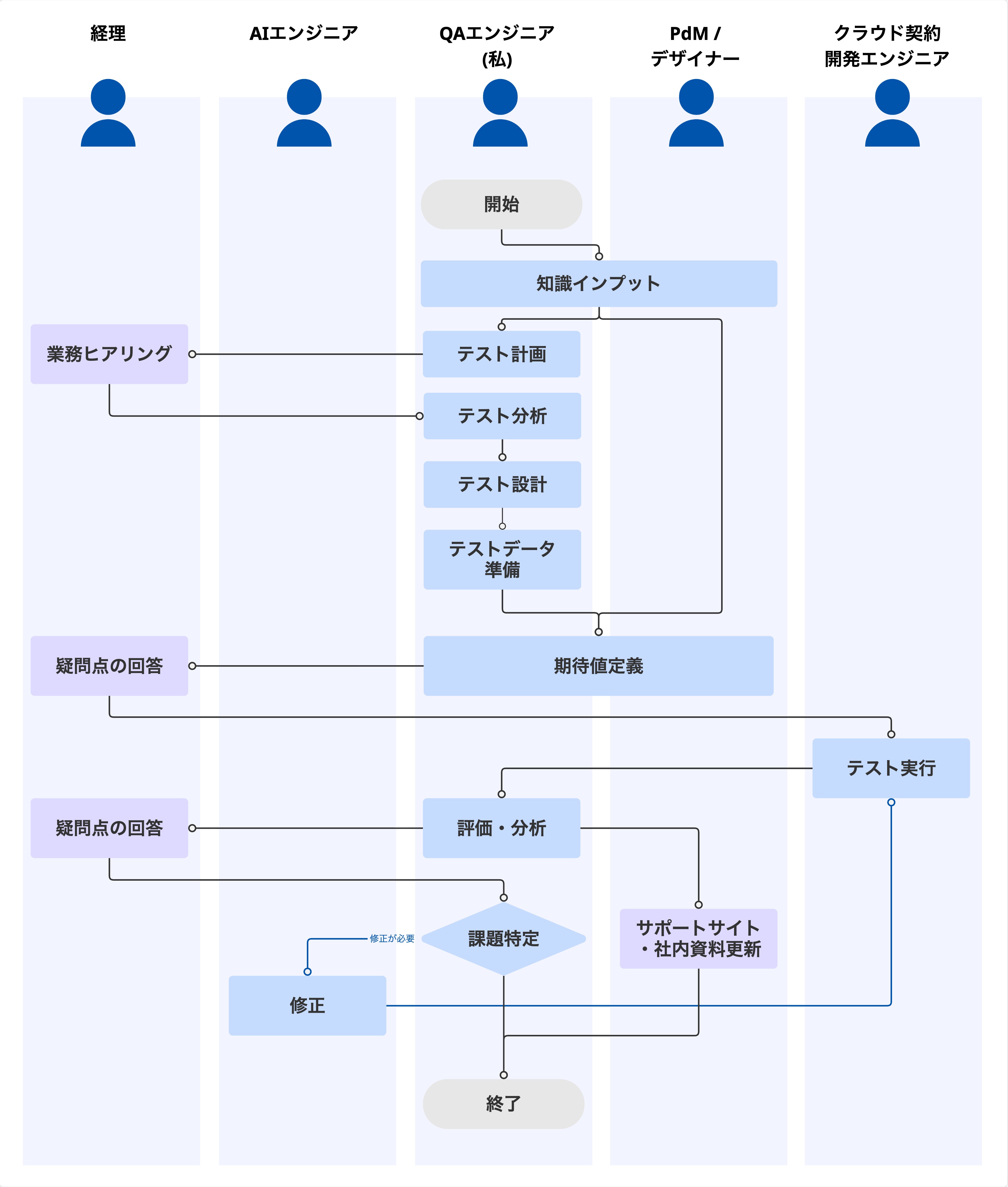
私たちはまず以下の検証プロセスを定義し、活動の土台を固めました。従来のテストの進め方と同様に、計画から改善までを順序立てて実行しました。
精度検証プロセス:
知識インプット → テスト計画 → テスト分析 → テスト設計 → テストデータ準備 → 期待値定義 → テスト実行 → 評価・分析 → 修正(実行-評価を繰り返す)
1. テスト計画
まずはテスト計画を作成し、検証の土台を固めました。そこで、以下のポイントを工夫しました。
役割分担の明確化:
「機能テスト」と「AIエージェントの精度検証」を明確に分離しました。
クラウド契約の開発チームは海外メンバーがメインとなっています。海外のQAエンジニアはプロダクト全体の機能テストに注力し、私はAIエージェントの精度検証のみに集中しました。AIエージェントから出力される日本語の内容の確からしさを海外メンバーが検証するのは難易度が高いため、役割を分けることは良いアプローチだったと思います。
知識のインプット:
Webで公開されているAIプロダクト品質保証ガイドラインを読み込み、必要な考え方を把握しました。このガイドラインがなかったら検証できていなかったと思うほど、自分の中では救世主の存在です。
並行して、新リース会計基準の知識を弊社のセミナー資料等から習得しました。弊社は2025年11月期に向けて新リース会計基準の早期適用準備を進めてきたため、経理の方に直接実務内容を質問することができました。
ゴールの定義:
AIプロダクトの品質保証では、機能テストとは異なる評価指標(正解率、偽陽性/偽陰性など)が必要です。それらの指標においてどのような点を重視するかを関係者に相談し、決定していきました。
定性ゴール: ユーザーの業務時間短縮。
重要メトリクス: 経理ヒアリングに基づき、「誤認識で業務を増やさない」ために「偽陰性の低下」を重視する。
副次ゴール: サポートサイト作成に向けて、AIエージェントの特性を文書化する。
このように、指標やゴールを計画時点で明らかにすることで検証活動のブレをできるだけ抑えることができました。
2. テスト分析・設計・準備
QAが最も活躍できるフェーズでありながら、AIエージェントの特性上、どのようなデータをどれぐらい準備すれば妥当なのか頭を悩ませました。
テスト分析
実際に使われる頻度の高い契約書の種類や業界、見落としてはいけないリスクを考慮し、「ユーザー」を理解した上でデータを選定しました。そこで、経理の方にヒアリングをしながら確認すべき観点やスコープを決定しました。
また、「リース識別エージェント」内にはテキスト読み取りのプロセスがあるため、AIプロダクト品質保証ガイドラインに基づき、頑健性(入力の変化に対して出力が変化しないかどうか)の観点も確認することにしました。この観点は、性能を把握して精度の向上に繋げたり、ゴールの1つであるサポートサイトに記載したりするためでもあります。
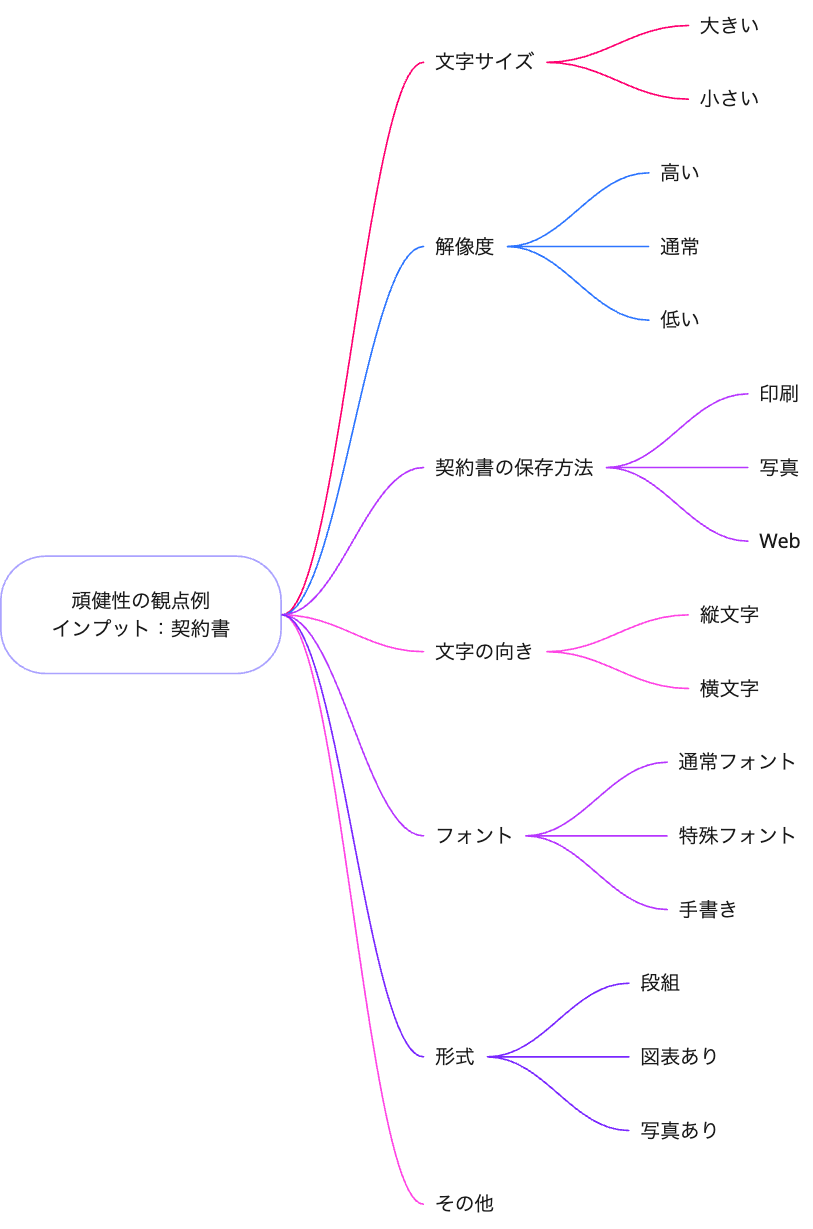
AIエージェントのテスト分析フェーズにおいては、従来の機能テストで培ってきた設計技法とは別の「現実性」や「表現の多様性」などの新たな視点が必要だと強く感じました。
組み合わせの考え方
エージェントによる出力項目が複数存在する場合、QAエンジニアとしてはデシジョンテーブルを使った組み合わせを検証したくなります。しかし、そのデータが現実で起こり得るかを確認し、意味のないテストデータの作成を最低限に留めることで、より効果的な検証が行えると思います。
「表現の多様性」の考慮
エージェントからYes/Noの2パターンの値が出力される場合、ただ単に2パターンのテストケースを作るだけでは足りない場合があります。その回答を導き出すための文章表現の多様性(明確/遠回し、日本語/英語、情報の欠落など)なども考慮することで、正しい回答が出力されるかどうかを検証することができます。
テストデータ準備
事前に収集できていたテストデータの契約書だけでは確認したい観点をすべて検証することができなかったため、LLMを活用してテストデータとなる契約書を作成し、検証範囲を補強しました。
期待値定義
精度検証における最大の課題は、「AIの出力に対する期待値の定義」です。困難だった要因は以下の3点です。
- 評価軸の違い: 単純なPass/Failでは評価できず、「どの程度正解に近いか」を測るためにはテストデータの期待値を一つ一つ定義し、出力結果と比較する必要があること。
- ドメイン知識: 新リース会計基準という高度な専門知識が不可欠なこと。
- 解釈の多様性: 人間でも解釈によって期待値が異なる場合があり、正解が一つに決まらないこと。
期待値を明確化するために、経理本部に相談しながらスピードと正確性を向上させました。
3. 実行・評価・改善
テスト実行
AIは「非決定論的」であるため、同じエージェント設定で同じインプットでも、アウトプットが異なることがあります。そのため、同じテストデータを3回実行して結果を比較しました。これにより、結果に連続した傾向があるのかどうかを分析できるようになりました。
評価・分析
AIの回答と期待値が異なるデータを抽出し、1つ1つの間違いの原因を丁寧に分析しました。この分析は精度改善のための重要なフェーズです。
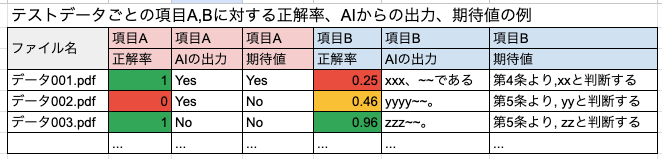
「正解率」の指標については、「このエージェントの精度は何%か?」と多くの方から質問されることが多いと思います。しかし、データセットが違えば正解率も大きく変わるため、システム全体の正解率を保証することはできません。そのため、「この観点のテストでは、X件の実行でY%の正解率だった」のようにデータセットをカテゴリ毎に共有することで、改善すべきポイントや傾向がわかるようにしました。
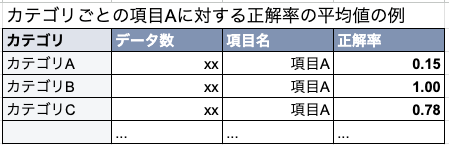
評価をするにあたって、PythonやExcel/Spread sheetのPivot tableなどを用いて実行結果を分かりやすい形式に変換・可視化するスキルが、関係者への素早い情報提供や判断のために必要でした。
その後の改善サイクル
課題リストを作成し、何を今すぐ修正すべきかをAIエンジニアと話し合いました。検証は何度も繰り返すため、加えた変更内容(コード、エージェントの設定、実行環境など)やデータの格納先を管理して認識を揃えると進めやすかったです。
リリース前の改善サイクルの大きな結果として、エラー率を大幅に下げ、安定性を向上させることができました。中でも「頑健性」のテストデータを作成したことがエラーの原因特定に繋がり、品質向上の手がかりを見つけることができました。
教訓
テストデータ量と期待値定義の工数を考慮する
今回は期待値定義に時間を要し、テストデータの量も相まってスケジュールが逼迫してしまいました。テスト計画時点で期待値定義に関わるメンバー全員と相談し、余裕のある工数を確保した方が良かったです。
実行コストやスケジュールを考慮しつつ、まずはミニマムなデータセットで大まかな傾向をつかみ、問題となった観点のデータを追加するアプローチが効率的だと感じます。
まとめ
知識ゼロからのスタートで迷うことがたくさんあった3ヶ月でしたが、最後まで進めることができたポイントをまとめました。
- ユーザーフォーカスの視点で意思決定をしたこと
- 計画を立て、スケジュールを共有しながら取り組んだこと
- 各専門知識を持ったメンバーを巻き込み、相談・合意しながら進めていけたこと
PdM/デザイナー/AIエンジニア/海外の開発エンジニア・QAエンジニア/経理/ビジネスメンバー含め、全員が役割を分担し、チームワークが発揮できたと思います。協力してくださった皆様、ありがとうございました。 これからも検証のプロセス改善や精度向上に尽力し、お客様により良い品質を届けていきたいです。
最後に
マネーフォワードではQAエンジニア/SDETを募集しています。スピード感を持って新しい挑戦をしたい方、お待ちしております!