
こんにちは。12/1 サービス基盤本部の本部長を務めている鈴木(@syou1024) です。
マネーフォワードの全社のサービスのインフラ関連の組織について、今までとこれからについて話そうと思います。同じような悩みを持つ方のヒントになったり、またマネーフォワードのSRE、インフラエンジニアに興味を持って頂けたら嬉しいです。
サービスのインフラチームの歴史
現在のマネーフォワードでは、全社のプロダクトのインフラを担当するサービスインフラチーム、幾つかのプロダクトの開発チームの中に存在するプロダクトのSREチームと、複数のインフラ、SREチームが存在します。
サービスインフラチームはサービ基盤本部に所属していて私が管掌しています。また、サービス基盤本部の本部長就任前にプロダクトのSREチームを一番最初に作ったのも私です。 マネーフォワードのインフラの組織が「なぜそうなってるのか?」。まずは私から見えてる歴史をお話しします。
黎明期(2012年〜2017年)
創業から2017年頃までサービスインフラチームとプロダクトの開発チームの役割は以下でした。
責務
- プロダクトの開発チームは機能開発にできる限り専念。
- 機能開発以外は全てサービスインフラチーム。
- サーバやネットワーク、データベース
- CICD。プロダクションだけでなく、各環境にアプリケーションを起動させること。
- 性能対応。
- モニタリング、プランニングとその対応。
- 何か問題があれば、サーバ追加&増強。
Pros
これによって以下のようなメリットを享受出来てました。
- プロダクト開発チームは機能開発に専念。
- 少しでも早くユーザに新しい機能を提供できる。
- サービスインフラチームにナレッジが集中して、効率的に開発できる。
Cons
しかし、少し考えれば分かるのですが、これらのメリットはプロダクトの数が少ないが故に享受できたメリットです。プロダクトの数が増えるに連れ、以下のようなデメリットが出てきます。 1. サービスインフラチームに業務が集中し、開発のボトルネックに。 1. サービスインフラチームの認知負荷の限界を超え、各プロダクトの状況を掴めず、ケアできない。
革新期(2018年〜2021年)
上の課題に対して、サービスインフラチームやマネーフォワード開発組織全体は以下のような対策を打ちます。
施策
- 【全社】プロダクト開発チームに責務を移行。
- 開発チームにSREチームを作ってインフラ業務を任せる。
- 【全社】マイクロサービス化
- プロダクト開発チームでインフラの責務を持つには、インフラを含めて面倒を見れる余裕が必要です。
- モノリスな環境では機能だけで手一杯で、そのチームに責務を渡すと今度はプロダクト開発チームの認知負荷の上限を超えてしまいます。
- サービスインフラの仕事を増やしつつ、プロダクト開発チームの認知負荷を一定以下に保つにはマイクロサービス化して、それ以外の認知負荷を下げるしかありません。
- 【サービスインフラ】クラウド化、コンテナ化を進めて、プロダクト開発チームでも見れるインフラ、容易にサービスを追加できるインフラに変えていく。
- この環境をServicePlatformと呼んでいます。
Pros
この施策は一定の効果を上げます。
- ServicePlatformに載り、かつ、ServicePlatformに必要な知識を自分たちで持てる開発チームはサービスインフラチームへの依存が減って、自分たちだけで開発サイクルを回せる。ボトルネックの解消。
- SREチームを作った開発チームはサービスインフラチームへの依存が減って、自分たちだけで開発サイクルを回せる。ボトルネックの解消。
Cons
しかし、まだまだ上手くいっておらず、新たな課題が発生しているのが今です。
- SRE技術や採用のナレッジが各部に散らばってしまい、開発組織の大きさを活かせない。
- インフラ機能の移行より開発組織の拡大が大きく、サービスインフラチームの負荷は軽減どころか増加している。
- プロダクトの開発チームにとってクラウド化、コンテナ化の技術難度や負荷が高く、進捗が出ていない。もっと早く移行を進める必要がある。
拡大期(2022年〜、これから一緒に作る未来)
この課題に対してどうするか? サービスインフラチームの考えてる解は以下です。
- サービスインフラチームはプラットフォーム開発チームに生まれ変わる。
- サービスインフラチームは各開発チームでSRE機能を持てるように支援、推進を行う。
ナレッジは人ではなく、プラットフォーム、ツール、プラクティスに貯めます。
- どこかのチームで得たナレッジは、プラクティスとしてドキュメントを整備し、他のチームからも引き出せるようにします。
- プラクティスのうち、自動化できるものはツールを開発し、ツールを使うことでより軽い労力でナレッジを活かします。(自動化)
- ツールのうち、可能なものはプラットフォームに反映させ、意識せずともナレッジを利用できてる状態を作ります。(自律化)
サービスインフラチームはプラットフォームを開発するチームに生まれ変わり、プロダクトの開発チームはプラットフォームを利用することで、全社のSREの知見を活かして開発できる世界を作ることが、私が考えてる未来です。
プラットフォームの開発するサービスインフラとプロダクトの開発チームの関係は、タスクの依頼によっては結ばれません。2つのチームはプラットフォームを介して関わります。 プラットフォームを作るチームと、利用するチームになります。
プラットフォームとは何か?
プラットフォームとは何か?イメージが浮かぶでしょうか?? サービスインフラチームが考えるプラットフォームは以下を実現します。
- サービスの安定稼働を実現できる。
- 最速のサービス開発を実現できる。
- イノベーション溢れるサービスの開発を実現できる。
もう少し具体的に見ていきます。 以下は僕の今のイメージです。僕の知識不足で考慮が至ってないところはあると思います。これからチーム内で話しあったり、開発者の人の意見をお伺いしながらより良いものに変わっていくはずですが、どんなことをやるのか大体のイメージを共有します。 また、全てこれから行うわけではありません。既に出来てるものも幾つかあります。
1. サービスの安定稼働が実現できるとは何か?
- 障害時に自動復旧する自律的なシステム
- このプラットフォームでは障害が起きても自動で復旧します。
- 安心なデプロイプロセス
- リリース時のユーザ影響を発生させないリリース
- BlueGreenが標準で搭載され、ユーザ影響を気にせずいつでもリリースできます。
- カナリーリリース提供
- 一部ユーザだけへのリリースが影響を最小限にしつつ、簡単にリリースできます。
- 高速なロールバック、エラーレート上昇による自動ロールバック
- いざリリース時に失敗してもエラーレートを監視し、問題が出たら自動で戻ります。
- 障害時の影響が限定化される。内部通信のアクセス制御やCircuitBreakerとか。
- 間違ったプログラムをリリースして暴走しても、他サービスに影響を与えず、ユーザ影響を限定化できる。
- 安心して構成変更
- gatekeeperやconftestなどで、セキュリティなど守るべきポイントが守られる。
- 今までインフラの構成変更はサービスインフラチームにレビューしてもらうことで品質を保証していたが、今後はテストによってプラットフォームを守られます。
- サービスインフラチームにレビューして貰わずとも、誰もが構成変更できる。
- 障害や性能が検証されて安心
- カオスエンジニアリング導入
- 意識せずとも障害テストが行われるし、どのサービスもが障害時の影響を加味し開発する未来の実現
- プロダクション性能に対するスマートなモニタリング
- 閾値だけでなく、AIや統計を見て変化を察知したり。
2. 最速のサービス開発を実現できる。
- 高速なテスト&デプロイ
- テストやデプロイを1秒でも早くする仕組みやツール、環境の提供
- 全て共通で扱え、各プロダクトにポリシーの無いもののプラクティスやモジュール準備
- 例えば、ログ出力などは共通で作れるはず。
- TimeStamp形式、ErrorLevel、ログ形式(Text?Json?など)、サービス間を跨るグローバルな識別子など)
- ProtoBufferの共通管理。インターフェースが分かる。
- 高速なBootStrap。
- 今はServicePlatformや開発環境でプロダクトを動かすまでの負荷が高い。
- 例えば、リポジトリ作成の延長で同じように以下のようなことを実現したい。
- Slackコマンドを実行すると、Service名(リポジトリ名)、ServicePlatformで動かすか?、開発環境で動かすか?、golangで動かすか、Railsが動かすか聞かれる。
- その回答に沿って、サンプルアプリがそのリポジトリに作られ、ServicePlatform、開発環境に自動でデプロイされ、それぞれの環境で動き出す。
- 上で考えたログの標準モジュールなど、標準的に必要なものは既に導入済み。
- 後は機能開発から開始。
- スケーラビリティ
- 基盤を利用するサービスが増えていっても水平にスケールしていく能力を持っている
- 十分に基盤の運用が自動化されており、基盤の利用サービスが増加しても運用負荷はほとんど増加しない
- 標準で開発速度指標を示すメトリクスの提供
3. よりイノベーション溢れるサービスの開発を実現できる。
- データ収集の仕組みがデフォルトで入っており、データ分析が容易にできる。
- ABテストが容易に実現できたり、リリースによってユーザ体験がどう変わった分かる。
- データからユーザの動向を掴み、よりユーザを意識した開発が可能。
- サービス間連携を容易に、サービス間のシナジー促進
- インターフェースが標準化されていて、それに則り開発が可能
- 各連携を容易に実現可能な通信制御
- マネーフォワード内や他社サービスとの連携両方が容易に実現し、シナジーを考えたときに容易に実現し検証し、アイデアの実現を後押し。
どうでしょうか?イメージ浮かんだでしょうか? 全社の知見をこういったプラットフォームに集積し、マネーフォワードの開発組織全体を繋げ、マネーフォワードの開発全体を加速させ、よりイノベーティブ溢れるものにする。 それがサービスインフラチームが変わりたい姿、作りたいものです。
どのように目指すか?
体制の話し
サービスインフラチームは今2チームに分かれています。Sakuraインターネット環境で作った環境のインフラタスクを見るSakuraチーム、AWS環境で作った環境のインフラタスクを見るAWSチーム。 そこから以下のような体制に生まれ変わろうと思っています。
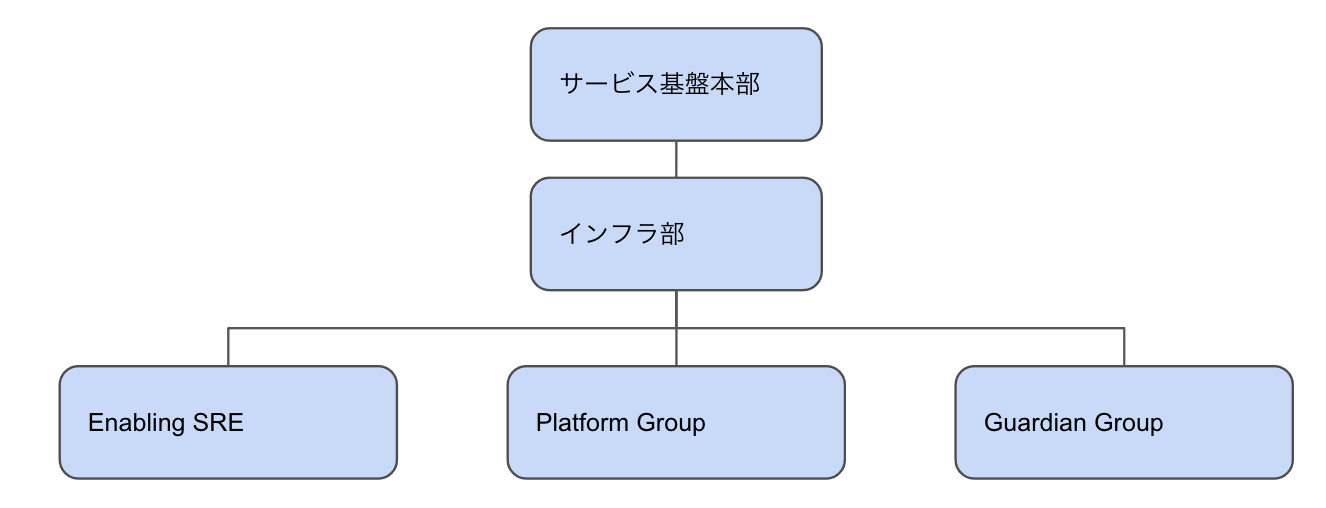
Platformチーム 全社を俯瞰し、上で語ったプラットフォームの開発を行います。 プラットフォームを通して、全社のエンジニアのDevEXや開発生産性の改善を実現します。
Enabling SREチーム 作ったプラットフォームを利用し、各プロダクトの開発チームがSRE相当のことを可能にするミッションを担います。プロダクト開発チームを支援し、SREのプラクティスの浸透や作ったプラットフォームに環境を移行し、SRE業務が可能なように変えます。
Guardianチーム 各プロダクトが抱えているユーザがいる以上、今のサービスインフラチームの役割をいきなり投げ出すことは出来ません。しかし、今の仕事を抱えたままではプラットフォームの開発に注力する時間は取れません。 そのため、1年〜2年、業務委託のチームを短期的に入れ、今抱えてる雑務をオフロードし、プラットフォームの開発に当たる時間を創出します。
ロードマップの話し
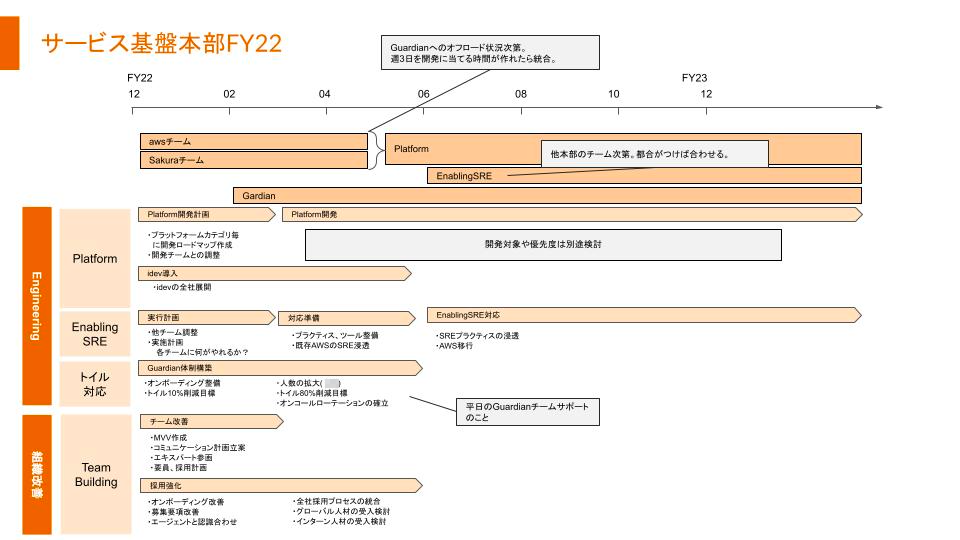
上は2022年に考えているサービスインフラチームのロードマップです。
ここ2,3ヶ月は上の体制を作るための準備期間に当たります。
- Platformは何をどのような順番で作っていくのか?
- EnablingSREは具体的に各プロダクト開発チームが何を出来るようにするのか?そのギャップを埋めるために何が必要なのか??
- Guardianチームへのオフロードを進め、Platform,EnablingSREチームを作る時間の創出
など。 まだ見えていないことも沢山あります。きっと壁にも当たるだろうと思っています。 それらは覚悟しつつ、乗り越え、半年後に上の体制を作って行きたい、そう考えています。
もう少し未来の話し
上の体制にはもう少し未来があります。
プラットフォームが良いものになってくると、サービスインフラチームに依頼する雑務がなくなってくるはずです。その時、Guardianチームは存在しなくなるはず。
プラットフォームが更に良くなると、EnablingSREチームがいなくともプロダクト開発チームで十分にプラットフォームを活用できるようになります。
プラットフォームをより良くしようとすると、専門分野に特化して理解する必要が出てきてPlatformチームをより細分化する必要が出てくるはずです。
その先のチームは以下のようになります。
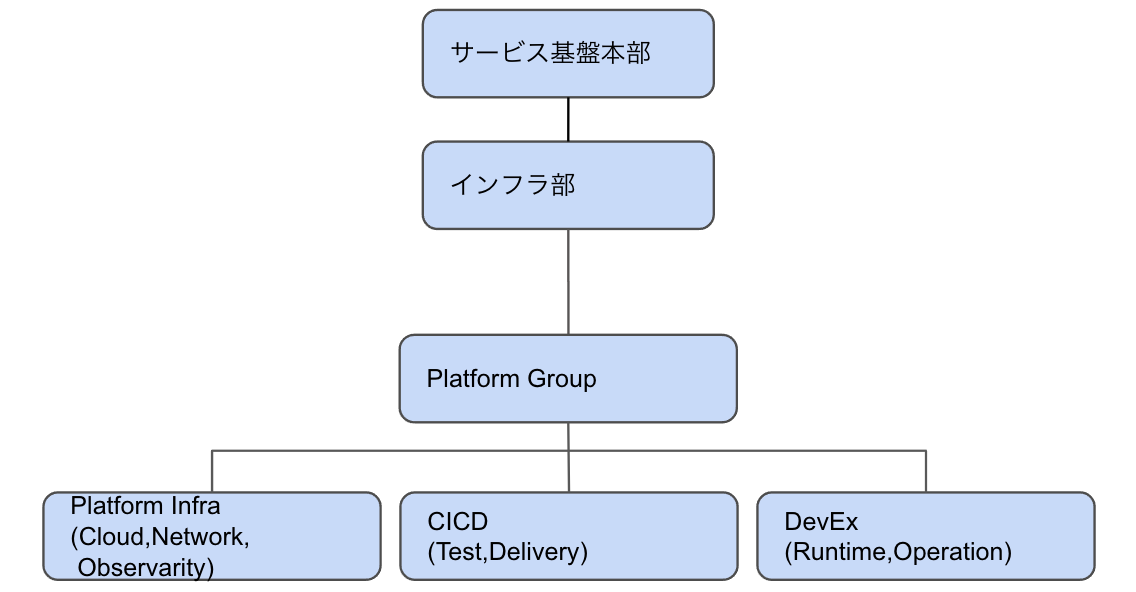
恐らく、PlatformGroupの仕事には何段階かあります。
Phase1. 国内の事例を追いつつ、プラットフォームを改善する。 最初はこの段階。 チームもPlatformGroupひとつ。 カバーする技術範囲も広いため、国内事例を追うのに精一杯。
Phase2. グローバルの最新事例を追って、プラットフォームを改善する。 チームメンバーが増えてきたら技術スタックによってチームを分割します。 より専門的に各技術スタックに集中することができ、より最新で高い価値を提供できるようになります。 恐らく、1チーム5〜10人という構成になると考えています。 プラットフォームに問題があった時のオンコールローテーションを組むために最低4人、exitやチーム間の異動の可能性も踏まえたバッファ入れて5人。
Phase3. 自ら事例を作り出し、プラットフォームを作り出す より洗練されてくると、マネーフォワードが最先端を作り出し、世の中に新しいソフトウェア、プラクティスを示します。最先端を作りたいエンジニアが魅力を感じ、ジョインしてくれます。
マネーフォワードの一つ先に進んでるメルカリ、その先の規模の楽天やYahoo、そしてGoogleやAmazon。そういった企業は、今の開発組織のあり方ではきっと目指せません。
多くのエンジニアの知識を集約し全体を底上げるプラットフォームと、プラットフォームと独立して開発、リリースサイクルを回せる自律した開発チームが必須だと考えています。そうでないと、何処かで開発組織をスケールできなくなる。
上のような会社を目指すために、システムのアーキテクチャや組織のあり方を変えていかなくちゃいけないと考えています。
最後に
これから変えていくマネーフォワードやサービスインフラチームにワクワクしませんか?私はこれから作り上げる未来にめっちゃワクワクしています。
私たちサービスインフラチームがこれを実現しないと、マネーフォワードは各プロダクトチームごとにしか成長できない、これを実現することによってマネーフォワード全体を後押しして、より大きな価値をユーザに届けられるようになる。 めっちゃ使命感持っています。
ただ上の未来を実現するためにはまだまだ人が足りません。 もしこの未来に興味あるよ、一緒に作りたいという方がいたらぜひ選考にご応募ください。
サービスインフラチームの募集 ←2021年12月現在だと内容が少し古いです:bow:追ってアップデートします。
正式選考でなく情報交換程度でも大丈夫です。少しでも興味あれば是非お話ししましょう。その際は、以下のいずれかでお声がけください。
twitter: @syou1024 Linkdlin: Link Meety: Link
マネーフォワードでは、エンジニアを募集しています。 ご応募お待ちしています。
【サイトのご案内】 ■マネーフォワード採用サイト ■Wantedly ■京都開発拠点
【プロダクトのご紹介】 ■お金の見える化サービス 『マネーフォワード ME』 iPhone,iPad Android
■ビジネス向けバックオフィス向け業務効率化ソリューション 『マネーフォワード クラウド』
■だれでも貯まって増える お金の体質改善サービス 『マネーフォワード おかねせんせい』