
こんにちは。id:Pocke です。
私は最近、Steep のメモリ使用量の改善に取り組んでいます。その過程で(意図せず) Steep の実行速度の改善に成功しました。 その中で行った、メモリ使用量の調査や、結果として実行速度が改善されたことは自分にとって中々楽しい体験でした。この記事では実行速度の改善に至るまでの経緯を紹介します。
記事中のソフトウェアは、執筆時点で最新のものを使用しています。具体的なバージョンは以下の通りです。
- Ruby: 3.3.4
- MemoryProfiler: 1.0.2
- Steep: 1.8.0.dev.1
TL;DR
- メモリ使用量の調査のために、
memory_profilergem を使った - それだけだと不十分なので、Ruby にパッチを当てた上で計測をした
- 結果として
steep checkの解析対象ファイル数が多い場合に速度が遅くなることが分かり、改善した
なぜメモリ使用量の改善が必要なのか
まず、私がメモリ使用量の改善に取り組んでいる背景を説明します。
大きめの Rails アプリケーションで Steep を使おうとすると、メモリの使用量の多さに気が付きます。手元にある中程度の規模の Rails アプリケーションで Steep の Language Server を動かしてみると、1プロセスあたり1.5GB程度のメモリを消費しています。
メモリを多く搭載した計算機が広く普及した現代では、ある程度気軽にメモリを使えます。とはいえ Steep の現状のメモリ使用量はあまり良いとは言えない状況でしょう。Language Server はエディタを開いている間、常駐するプロセスです。また複数のプロジェクトのために同時に複数のエディタを開けば、その数だけ Steep のプロセスが立ち上がります。その上 Steep は複数のワーカープロセスを立ち上げるため、高速に動作させるためにはさらに多くのメモリを必要とします。
このような事情を考えると、たとえ1プロセスのメモリ使用量が1.5GBであっても、計算機全体としては常にそれを数倍したメモリが必要とされます。 より Steep を広く使ってもらうためには、メモリ使用量の改善が必要だと考えています。
メモリ使用量の内訳を探る
このような問題に対処するには、まず計測、そして問題の特定が必要です。 Ruby でメモリの使用をプロファイリングするツールとして、memory_profiler gem があります。今回はこの gem を使用して Steep のメモリ使用についてのプロファイリングを行いました。
memory_profiler でプロファイリングする
では memory_profiler を使って、Steep をプロファイリングしてみましょう。
今回は Steep に次のパッチを当てて、プロファイリングを行いました。1
diff --git a/exe/steep b/exe/steep index 73fab66a..454f58a7 100755 --- a/exe/steep +++ b/exe/steep @@ -6,6 +6,9 @@ $LOAD_PATH << Pathname(__dir__) + "../lib" require 'steep' require 'steep/cli' +require 'memory_profiler' + +MemoryProfiler.start begin exit Steep::CLI.new(argv: ARGV.dup, stdout: STDOUT, stderr: STDERR, stdin: STDIN).run @@ -15,4 +18,7 @@ rescue => exn STDERR.puts " #{t}" end exit 2 +ensure + report = MemoryProfiler.stop + report.pretty_print end
その結果、次のような出力が得られました。出力全文は長いので、今回注目した箇所を抜粋します。
Total allocated: 2940741904 bytes (8583654 objects) Total retained: 2218328 bytes (17013 objects) allocated memory by gem ----------------------------------- 2056526976 set 543648001 rbs-3.5.1 201891696 pathname 46186750 json-2.7.2 46049095 steep/lib 32251386 language_server-protocol-3.17.0.3 (中略) allocated memory by file ----------------------------------- 2056526976 /path/to/lib/ruby/3.3.0/set.rb 282735256 /path/to/lib/ruby/gems/3.3.0/gems/rbs-3.5.1/lib/rbs/parser_aux.rb 201891696 /path/to/lib/ruby/3.3.0/pathname.rb (中略) allocated memory by location ----------------------------------- 2053446528 /path/to/lib/ruby/3.3.0/set.rb:286 282706936 /path/to/lib/ruby/gems/3.3.0/gems/rbs-3.5.1/lib/rbs/parser_aux.rb:20 82090320 /path/to/lib/ruby/3.3.0/pathname.rb:51
この結果を見ると、確保されているメモリの大部分が set によるものだということが分かります。
先頭に表示されている Total allocated と最後のセクションの allocated memory by location から、set.rbの286行目だけで2,053,446,528 / 2,940,741,904バイト、つまり全体の約70%を占めていることが分かります。
メモリの確保が1箇所にこれだけ集中していることは、そこが一種のボトルネックになっていることを示唆しています。
ではどのようなコードがメモリを確保しているのでしょうか?set.rbを見てみると、286行目はinitialize_dupメソッドの定義でした。
def initialize_dup(orig) super @hash = orig.instance_variable_get(:@hash).dup # ここが286行目 end
initialize_dupはdupの内部で呼ばれるメソッドなので、どこかで大きなSetオブジェクトをdupしていると推測できます。
しかしこのボトルネックを解消しようとすると1つの問題が立ちはだかります。
Set#dupが多くのメモリを消費していることがわかっても、これだけではどこでSet#dupが呼ばれているのかは分かりません。Steep のコードを修正したくても、どこを直したらよいのかが分からないのです。
この問題を解決するためには、Set#dupの定義場所ではなく、Set#dupが呼ばれる場所を取得できると良いでしょう。
Set#dupが呼ばれているのはこの定義場所よりもバックトレースを1つ遡った場所ですので、何かしらの方法でバックトレースを1つ遡ることができれば、期待する情報を取得できそうです。
memory_profiler の実装を調査する
バックトレースを遡る方法を探るために、まずは memory_profiler の実装を読んでみましょう。memory_profiler に何らかのパッチを当てることで、期待する情報を手に入れられるかもしれません。 幸いなことに memory_profiler は Ruby で書かれているため、C言語に詳しくなくてもかんたんに読み解くことができます。
MemoryProfiler.start, MemoryProfiler.stop
まずエントリポイントであるMemoryProfiler.start及びMemoryProfiler.stopの定義を見てみましょう。
https://github.com/SamSaffron/memory_profiler/blob/v1.0.2/lib/memory_profiler.rb#L19-L30
def self.start(opts = {}) unless Reporter.current_reporter Reporter.current_reporter = Reporter.new(opts) Reporter.current_reporter.start end end def self.stop Reporter.current_reporter.stop if Reporter.current_reporter ensure Reporter.current_reporter = nil end
この定義を見ると、それぞれMemoryProfiler::Reporterのインスタンスのstart, stopメソッドを呼び出していることが分かります。
MemoryProfiler::Reporter#start
では次にMemoryProfiler::Reporter#startを見てみましょう。
https://github.com/SamSaffron/memory_profiler/blob/v1.0.2/lib/memory_profiler/reporter.rb#L36-L43
def start 3.times { GC.start } GC.start GC.disable @generation = GC.count ObjectSpace.trace_object_allocations_start end
ここでは GC を止めて、ObjectSpace.trace_object_allocations_startを呼んでいます。これは Ruby が提供する、オブジェクトの割り当てをトレースする機能です。
MemoryProfiler::Reporter#stop
次にMemoryProfiler::Reporter#stopを見てみましょう。長いため一部を抜粋します。
https://github.com/SamSaffron/memory_profiler/blob/v1.0.2/lib/memory_profiler/reporter.rb#L36-L43
def stop ObjectSpace.trace_object_allocations_stop allocated = object_list(generation) retained = StatHash.new.compare_by_identity # (中略) @report_results = Results.new @report_results.register_results(allocated, retained, top) end
ここで注目したいのはobject_listメソッドです。どうやらこのメソッドを使って、allocate されたオブジェクトの一覧を取得しているようです。
MemoryProfiler::Reporter#object_list
ということでobject_listメソッドの定義を見てみましょう。こちらも長いため概略を抜粋します。
https://github.com/SamSaffron/memory_profiler/blob/v1.0.2/lib/memory_profiler/reporter.rb#L88-L125
def object_list(generation) result = StatHash.new.compare_by_identity ObjectSpace.each_object do |obj| file = ObjectSpace.allocation_sourcefile(obj) || "(no name)" begin line = ObjectSpace.allocation_sourceline(obj) result[obj.__id__] = MemoryProfiler::Stat.new(class_name, gem, file, location, memsize, string) rescue end end result end
これを見ると、どうやらすべてのオブジェクトに対してObjectSpace.allocation_sourcefile及びObjectSpace.allocation_sourcelineメソッドを呼び、そのオブジェクトが allocate された位置を取得しているようです。
これらのメソッドにバックトレース上で1つ上の位置情報を返させることができれば、目的を達成できそうです。
しかし残念ながらこれらのメソッドの挙動を変えるようなオプションは用意されていません。ドキュメントによると、これらは対象となるobjectのみを引数として受け取ることが分かります。
https://docs.ruby-lang.org/en/3.3/ObjectSpace.html#method-c-allocation_sourcefile
ここまでで、memory_profilerのコードを変更して目的を達成するのは難しそうだと分かりました。
バックトレースを1つ遡るには、オブジェクトが実際に確保されたタイミングで処理を実行する必要がありそうです。
そのためには、ObjectSpace.allocation_sourcefileなどのメソッドの挙動を変更する必要があるでしょう。ということでこのメソッドの定義を見ていきましょう。
ObjectSpace の実装を調査する
ObjectSpace.allocation_sourcefileなどのメソッドは、Ruby の標準ライブラリであるobjspaceで定義されています。
標準ライブラリは Ruby 本体のリポジトリ内にコードが存在します。ということで、Ruby 本体のリポジトリを見ていきましょう。
allocation_sourcefile
まずはallocation_sourcefileメソッドの定義を見てみます。
このメソッドはext/objspace/object_tracing.cに定義されています。2
https://github.com/ruby/ruby/blob/v3_3_4/ext/objspace/object_tracing.c#L581-L582
https://github.com/ruby/ruby/blob/v3_3_4/ext/objspace/object_tracing.c#L439-L450
rb_define_module_function(rb_mObjSpace, "allocation_sourcefile", allocation_sourcefile, 1);
static VALUE allocation_sourcefile(VALUE self, VALUE obj) { struct allocation_info *info = lookup_allocation_info(obj); if (info && info->path) { return rb_str_new2(info->path); } else { return Qnil; } }
名前の通り、allocation_sourcefile関数がこのメソッドの実態です。
この関数はまずlookup_allocation_info関数を呼んで、引数のオブジェクトに対応するallocation_info構造体を取得しています。
そしてその構造体のpathメンバを返り値として返しています。つまりpathがセットされている箇所を見つけると良さそうです。
newobj_i
このpathは、同じくobject_tracing.c内のnewobj_i関数でセットされています。少し長いので、関連するところだけ抜粋します。
https://github.com/ruby/ruby/blob/v3_3_4/ext/objspace/object_tracing.c#L74-L114
static void newobj_i(VALUE tpval, void *data) { rb_trace_arg_t *tparg = rb_tracearg_from_tracepoint(tpval); VALUE path = rb_tracearg_path(tparg); struct allocation_info *info; const char *path_cstr = RTEST(path) ? make_unique_str(arg->str_table, RSTRING_PTR(path), RSTRING_LEN(path)) : 0; st_data_t v; info = (struct allocation_info *)ruby_xmalloc(sizeof(struct allocation_info)); info->path = path_cstr; }
これを見ると、rb_tracearg_path関数で取得したpathを(多少加工した上で)構造体にセットしていることが分かります。3
rb_tracearg_path
ではrb_tracearg_path関数を見ていきましょう。これはファイルが変わってvm_trace.cに定義されています。
https://github.com/ruby/ruby/blob/v3_3_4/vm_trace.c#L887-L892
VALUE rb_tracearg_path(rb_trace_arg_t *trace_arg) { fill_path_and_lineno(trace_arg); return trace_arg->path; }
fill_path_and_linenoでパスと行番号を取得してセットしているようですね。
fill_path_and_lineno
fill_path_and_lineno関数です。これもvm_trace.cに定義されています。
https://github.com/ruby/ruby/blob/v3_3_4/vm_trace.c#L873-L879
static void fill_path_and_lineno(rb_trace_arg_t *trace_arg) { if (UNDEF_P(trace_arg->path)) { get_path_and_lineno(trace_arg->ec, trace_arg->cfp, trace_arg->event, &trace_arg->path, &trace_arg->lineno); } }
どうやら実態はget_path_and_lineno関数のようです。
get_path_and_lineno
ということでget_path_and_lineno関数を見ます。やっと目的の関数にたどり着きました。
https://github.com/ruby/ruby/blob/v3_3_4/vm_trace.c#L694-L716
static void get_path_and_lineno(const rb_execution_context_t *ec, const rb_control_frame_t *cfp, rb_event_flag_t event, VALUE *pathp, int *linep) { cfp = rb_vm_get_ruby_level_next_cfp(ec, cfp); if (cfp) { const rb_iseq_t *iseq = cfp->iseq; *pathp = rb_iseq_path(iseq); if (event & (RUBY_EVENT_CLASS | RUBY_EVENT_CALL | RUBY_EVENT_B_CALL)) { *linep = FIX2INT(rb_iseq_first_lineno(iseq)); } else { *linep = rb_vm_get_sourceline(cfp); } } else { *pathp = Qnil; *linep = 0; } }
このメソッドでは、まずrb_vm_get_ruby_level_next_cfpで Ruby レベルのcfpを取得しています(cfpは、Control Frame Pointer の略かな)。cfpは、バックトレースの1行に対応していると考えてよいでしょう。
その後、cfpからパスと行番号の情報を取得し、引数のポインタにセットしています。
このget_path_and_lineno関数を修正すれば、set.rbを1つ遡り、目的のSet#dupが呼ばれた場所のファイル名と行番号を取得できそうです。
Ruby にパッチを当てる
さて、ここまででObjectSpace.allocation_sourcefileなどのメソッドが返す値を変えるには、どこを修正すればよいかが分かりました。
実際にこれを修正してみましょう。
次の方針でget_path_and_lineno関数に修正を行います。
cfpを取得するcfpからパスを取得する- パスが
set.rbであれば、1つ上のcfpを取得し、2に戻る
そしてこの方針で作成したパッチが次になります。
diff --git a/ext/objspace/object_tracing.c b/ext/objspace/object_tracing.c index c1c93c51f5..7bb7c7849c 100644 --- a/ext/objspace/object_tracing.c +++ b/ext/objspace/object_tracing.c @@ -77,8 +77,8 @@ newobj_i(VALUE tpval, void *data) struct traceobj_arg *arg = (struct traceobj_arg *)data; rb_trace_arg_t *tparg = rb_tracearg_from_tracepoint(tpval); VALUE obj = rb_tracearg_object(tparg); - VALUE path = rb_tracearg_path(tparg); - VALUE line = rb_tracearg_lineno(tparg); + VALUE path = rb_tracearg_path2(tparg); + VALUE line = rb_tracearg_lineno2(tparg); VALUE mid = rb_tracearg_method_id(tparg); VALUE klass = rb_tracearg_defined_class(tparg); struct allocation_info *info; diff --git a/include/ruby/debug.h b/include/ruby/debug.h index f7c8e6ca8d..b018cbc4e5 100644 --- a/include/ruby/debug.h +++ b/include/ruby/debug.h @@ -507,6 +507,7 @@ RBIMPL_ATTR_NONNULL(()) * @return otherwise Its line number. */ VALUE rb_tracearg_lineno(rb_trace_arg_t *trace_arg); +VALUE rb_tracearg_lineno2(rb_trace_arg_t *trace_arg); RBIMPL_ATTR_NONNULL(()) /** @@ -517,6 +518,7 @@ RBIMPL_ATTR_NONNULL(()) * @retval otherwise Its path. */ VALUE rb_tracearg_path(rb_trace_arg_t *trace_arg); +VALUE rb_tracearg_path2(rb_trace_arg_t *trace_arg); RBIMPL_ATTR_NONNULL(()) /** diff --git a/vm_trace.c b/vm_trace.c index c2762b73f2..4da16e8516 100644 --- a/vm_trace.c +++ b/vm_trace.c @@ -891,6 +891,59 @@ rb_tracearg_path(rb_trace_arg_t *trace_arg) return trace_arg->path; } + +static void +get_path_and_lineno2(const rb_execution_context_t *ec, const rb_control_frame_t *cfp, rb_event_flag_t event, VALUE *pathp, int *linep) +{ + cfp = rb_vm_get_ruby_level_next_cfp(ec, cfp); +cfp_back: + + if (cfp) { + const rb_iseq_t *iseq = cfp->iseq; + *pathp = rb_iseq_path(iseq); + + if (!memcmp(RSTRING_PTR(*pathp), "/path/to/lib/ruby/3.3.0/set.rb", RSTRING_LEN(*pathp))) { + cfp = rb_vm_get_ruby_level_next_cfp(ec, RUBY_VM_PREVIOUS_CONTROL_FRAME(cfp)); + goto cfp_back; + } + + if (event & (RUBY_EVENT_CLASS | + RUBY_EVENT_CALL | + RUBY_EVENT_B_CALL)) { + *linep = FIX2INT(rb_iseq_first_lineno(iseq)); + } + else { + *linep = rb_vm_get_sourceline(cfp); + } + } + else { + *pathp = Qnil; + *linep = 0; + } +} + +static void +fill_path_and_lineno2(rb_trace_arg_t *trace_arg) +{ + if (trace_arg->path == Qundef) { + get_path_and_lineno2(trace_arg->ec, trace_arg->cfp, trace_arg->event, &trace_arg->path, &trace_arg->lineno); + } +} + +VALUE +rb_tracearg_lineno2(rb_trace_arg_t *trace_arg) +{ + fill_path_and_lineno2(trace_arg); + return INT2FIX(trace_arg->lineno); +} + +VALUE +rb_tracearg_path2(rb_trace_arg_t *trace_arg) +{ + fill_path_and_lineno2(trace_arg); + return trace_arg->path; +} + static void fill_id_and_klass(rb_trace_arg_t *trace_arg) {
rb_tracearg_path, rb_tracearg_linenoに対して、それぞれ2という接尾辞をつけた関数を追加し、それを使うようにしました。
これらの関数からはget_path_and_lineno2関数を呼んでおり、これがこのパッチの中心です。
この関数ではmemcmpでパスを確認し、set.rbであればrb_vm_get_ruby_level_next_cfp(ec, RUBY_VM_PREVIOUS_CONTROL_FRAME(cfp))でcfpを1つ遡り、処理を戻しています。
チェックするパスを決め打ちにしているとても雑なパッチですが、ひとまずこれで用が足ります。このパッチを当てたうえで Ruby をビルドし、もう一度memory_profilerを動かしてみましょう。
MemoryProfiler で再度計測する
先ほどのパッチを当てて再度計測をすると、次の結果が得られました。
Total allocated: 2940742024 bytes (8583657 objects) Total retained: 2218328 bytes (17013 objects) allocated memory by gem ----------------------------------- 2101454375 steep/lib 544769697 rbs-3.5.1 201891696 pathname 46186750 json-2.7.2 32251386 language_server-protocol-3.17.0.3 (中略) allocated memory by file ----------------------------------- 2067148460 /path/to/lib/steep/server/master.rb 282735256 /path/to/lib/ruby/gems/3.3.0/gems/rbs-3.5.1/lib/rbs/parser_aux.rb 201891696 /path/to/lib/ruby/3.3.0/pathname.rb (中略) allocated memory by location ----------------------------------- 1706221088 /path/to/lib/steep/server/master.rb:46 348159552 /path/to/lib/steep/server/master.rb:65 282706936 /path/to/lib/ruby/gems/3.3.0/gems/rbs-3.5.1/lib/rbs/parser_aux.rb:20 82090320 /path/to/lib/ruby/3.3.0/pathname.rb:51
出力結果からset.rbが消えて、lib/steep/server/master.rbが新たに現れています。これで問題の特定に一歩前進しましたね!
では該当箇所の実装を見てみましょう。
master.rbの46行目と65行目が問題の箇所のようです。
https://github.com/soutaro/steep/blob/v1.8.0.dev.1/lib/steep/server/master.rb#L45-L47
https://github.com/soutaro/steep/blob/v1.8.0.dev.1/lib/steep/server/master.rb#L64-L66
def all_paths library_paths + signature_paths + code_paths # ここが46行目 end # 中略 def unchecked_paths all_paths - checked_paths # ここが65行目 end
all_pathsとunchecked_pathsの2つのメソッドの中で問題が起きていることが分かりました。原因の箇所にたどり着いたので、あとは解決するコードを書くだけです!
修正方法
問題を解決するために、これらのメソッドの呼び出し箇所を見てみましょう。これらのメソッドは、同じファイルのpercentageメソッドとfinished?メソッドから呼ばれています。
https://github.com/soutaro/steep/blob/v1.8.0.dev.1/lib/steep/server/master.rb#L41-L43
https://github.com/soutaro/steep/blob/v1.8.0.dev.1/lib/steep/server/master.rb#L60-L62
def percentage checked_paths.size * 100 / all_paths.size end # (中略) def finished? unchecked_paths.empty? end
これらのメソッドでは、all_pathsやunchecked_pathsの中身には関心がなく、要素数にのみ関心があることがわかります。つまり巨大なSetオブジェクトを作らずに、そのサイズだけを取得すれば良さそうです。
この方針で書いたパッチが以下になります。
diff --git a/lib/steep/server/master.rb b/lib/steep/server/master.rb index a359fc61d..a62ec4620 100644 --- a/lib/steep/server/master.rb +++ b/lib/steep/server/master.rb @@ -39,7 +39,7 @@ def total end def percentage - checked_paths.size * 100 / all_paths.size + checked_paths.size * 100 / total end def all_paths @@ -58,7 +58,7 @@ def checked(path) end def finished? - unchecked_paths.empty? + total <= checked_paths.size end def unchecked_paths
totalという、library_paths.size + signature_paths.size + code_paths.sizeを行うメソッドが存在していたので、それを使用しました。
これで挙動を維持したうえで、大きなSetオブジェクトの確保を防ぐことができます。
なお残念ながら、この修正は当初の目的であったメモリ使用量にはあまり影響がないことが予想されます。
なぜならばall_pathsやunchecked_pathsによって生成されるSetオブジェクトはすぐに不要になる短命なオブジェクトであり、一瞬メモリを確保したとしても、すぐに GC によって解放されるためです。
とはいえ巨大なSetオブジェクトの確保が減るため、実行速度の改善につながることが期待できます。最初の目的とは違いますが実行速度の改善も意義がありますので、それが改善されているかをベンチマークを取って確認してみましょう。
改善結果の計測
改善結果を見るために早速ベンチマークを…と言いたいところですが、その前に一度立ち止まって、この問題がどのようなケースで起きるかをもう少し考えてみましょう。
今回修正したpercentageとfinished?メソッドは、どちらも解析の進捗を表すメソッドです。これらのメソッドは解析の進捗を得るため、Steep の解析が1ファイル終わるごとに呼ばれています。つまり、解析対象のファイル数に対して線形に呼ばれる回数が増加します。
また今回問題となっていたall_pathsは、解析対象のファイルパスの一覧です。つまり解析対象のファイル数に対して、確保するメモリの量も線形に増加します。4
これらの理由から、今回の修正は解析対象のファイル数が多い場合に、特に大きく効果が見られることが期待できます。これを踏まえたうえでベンチマーク用の環境を作ってみましょう。5
ベンチマーク用の環境
上記のことに留意しつつ、次のコードを使ってベンチマークを行う環境を作成しました。
# Usage: ruby setup.rb 100 require 'pathname' lib = Pathname('lib').tap { _1.rmtree; _1.mkpath } sig = Pathname('sig').tap { _1.rmtree; _1.mkpath } ARGV.first.to_i.times do |i| lib.join("foo#{i}.rb").write(<<~RUBY) class Foo#{i} end RUBY sig.join("foo#{i}.rbs").write(<<~RUBY) class Foo#{i} end RUBY end
引数に渡した数字の分、クラス定義をしているだけの.rbファイルと.rbsファイルを生成しています。
これならば型検査にはほとんど時間がかからないため、ファイル数によって変動する部分のパフォーマンスに注目して計測ができます。
ベンチマーク
上記環境でsteep checkコマンドを実行し、その実行時間を計測することでベンチマークを行いました。ファイル数が0から10,000までの範囲で計測をしました。6
その結果が次の表になります。
| ファイル数 | 0 | 1 | 10 | 100 | 1000 | 2000 | 4000 | 6000 | 8000 | 10000 |
|---|---|---|---|---|---|---|---|---|---|---|
| before | 2.47 | 2.62 | 2.41 | 2.81 | 7.79 | 20.86 | 76.18 | 171.09 | 304.31 | 566.54 |
| after | 2.46 | 2.42 | 2.53 | 2.92 | 7 | 13.3 | 29.55 | 55.55 | 82.18 | 194.08 |
これをグラフにすると以下になります。
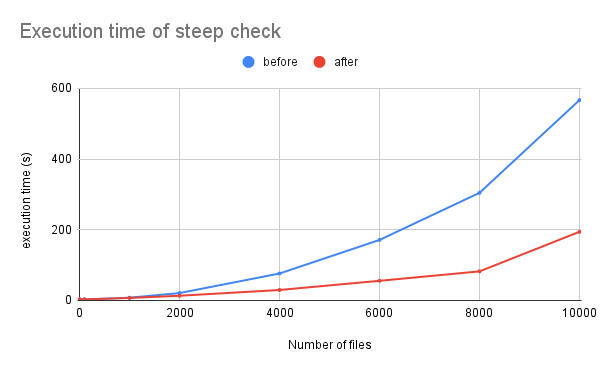
これを見ると、速度が改善されており、またファイル数が増えるほどその差が顕著になっていることが分かります。
memory_profilerでの計測
このスクリプトで4,000個のファイルを作った環境でmemory_profilerを実行してみると、パッチを当てる前後で以下の出力が得られました。
before
Total allocated: 7563837242 bytes (5427818 objects) Total retained: 1062365 bytes (171 objects) allocated memory by gem ----------------------------------- 7114488384 set 253915960 pathname 53144417 steep/lib 47872344 language_server-protocol-3.17.0.3 46181320 json-2.7.2 29675372 rbs-3.5.1 12868648 uri 3050296 other 2588320 activesupport-7.1.3.4 (後略)
after
Total allocated: 450887826 bytes (5314647 objects) Total retained: 1062365 bytes (171 objects) allocated memory by gem ----------------------------------- 253915960 pathname 53144417 steep/lib 47872472 language_server-protocol-3.17.0.3 46181320 json-2.7.2 29675372 rbs-3.5.1 12868648 uri 3050296 other 2588320 activesupport-7.1.3.4 1538880 set (後略)
Total allocated と、setによるメモリの確保が大きく減っていることが分かります。このパッチが意図通りに動いていることが確認できました。
ということで Steep の速度の問題を改善することができました。この修正は以下の pull request で行われ、すでにマージされています。おそらく Steep の次のリリースに含まれることになるでしょう。
最後に
今回は私が行った Steep の速度改善を、その経過に重点を置いて紹介しました。これが誰かの興味を満たすものになっていれば幸いです。
今回果たせなかったメモリ使用量の改善には引き続き取り組んでいます。現在はそのための道具として、Ruby 向けの新しいメモリプロファイラを開発中です。7 まだ完璧ではありませんが、そのうちこちらも記事で紹介したいと考えています。
また今回は Ruby にパッチを当てることでバックトレースから欲しい情報を手に入れましたが、Ruby にパッチを当てなくともこれができるようになっているとより便利なのではないかと思っています。
set.rbだけでなく、pathname.rbでも同様に呼び出し元を知りたいケースが実際にあったので、需要がある機能なのではないかと考えています。
気が向いたら機能の提案をしてみようかなと考えています(でも、いい感じのインターフェイスを考えるのが難しそうだよなあ)。
- 後から気がついたのですが、このパッチだと Steep の master プロセスのプロファイリングになっていて、型検査を行う worker プロセスのプロファイリングにはなっていませんでした。↩
-
C で定義されたメソッドを探すときは
"allocation_sourcefile"のようにメソッド名にクォートを含めて検索すると、定義位置が見つけやすく便利です。↩ - 省略していますが、行番号も同様に取得されています。↩
-
「つまり実行時間も線形に伸びるのではないか」と当初予想していたのですが、記事を書くにあたって
mallocの時間計算量を調べたところ、計算量は一概には言えないようです。むずかしい……↩ - 最初この関係に気がついておらず、適当な Rails アプリでベンチマークを取ったため、実行速度の差がほとんど確認できず少し凹んでいました。何を改善しているのかを正しく理解することは重要ですね。↩
-
10,000ファイルは非現実的な仮定だと思われる方もいるかも知れませんが、たとえば GitLab のリポジトリで
git ls-files app/ lib/ | grep '\.rb$' | wc -lとすると9,503ファイル見つかるため、案外現実的なファイル数です。↩ - https://github.com/pocke/majo↩