
ご無沙汰しております。
そろそろ1023回目の夏ですかね……
暑いですからね、銀色でも聴きながら読んでいただけたら幸いです。
僕は永遠にゴールできない()
Transformerのモデルをレイヤーごとに分解することでコストを削減した話
どうもCTO室AI推進部とグループ会社HiTTOで兼務中の@ken11です。
今日は 久しぶりに 真面目な話をしたいと思います。
掲題の通りですが、特定のシチュエーションにおいてTransformerのモデルのレイヤーを分解することは有効な技ですよという話ですね。
Transformerのモデルによる推論
そもそもTransformerとはなにかというと、最近流行りのGPTとかもそうですがモダンなNLP系の機械学習モデルでよく採用されているモデルのことですね。
詳しいことはWikipediaあたりを読んでください。
ここではTransformer自体の説明は省略させていただきます。
で、このTransformerの機械学習モデルですが、実際のところ多数のレイヤーから構成されており、推論時には以下のような処理が行われています。
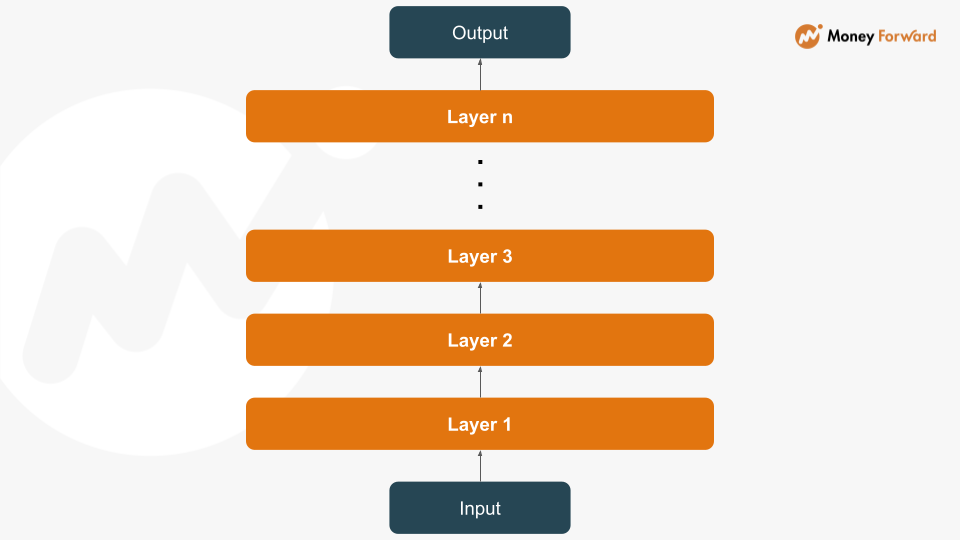
今回はこのTransformerの機械学習モデルを多数使用しなければならない場合において、レイヤーを分解することで処理を軽くできる(≒コスト削減できる)ケースが存在するという話をしたいと思います。
レイヤー分解
では実際にレイヤーを分解する、そしてコスト削減に繋がるというのはどういう話なのか説明していきたいと思います。
以下のようなケースについて考えます。
多数の機械学習モデル(Transformerでつくられている)を使ってリアルタイムで推論を行うサービスです。
モデルがある程度大きくなる場合、ロード時間が発生すると推論処理のレスポンスが遅くなってしまうので、モデルをロードした状態でサーバを稼働させることになるかと思います。(リクエストごとにモデルをロードする余裕はない)
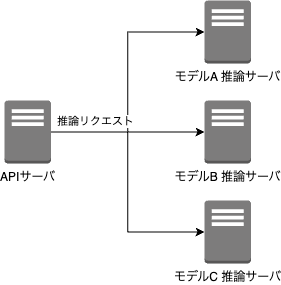
この場合、推論サーバのメモリ・GPU等の状況にもよりますが、やはり多数のモデルを積載することは困難であり、推論用のサーバを複数用意する必要性が発生し結果的にコストが膨らんでしまいます。
ここで重要になるのが、多数の機械学習モデルを使って推論サービスを構成する場合に本当にすべてのレイヤーが異なるのか? ということです。
Transformerの機械学習モデルを使う場合、ファインチューニングをして用途や要件ごとにモデルを切り替えるケースが多いのではないでしょうか?
もちろん全く異なるモデルを多数使うケースもあると思いますが、ある程度共通のレイヤーを持ったモデルを多数展開しているのであれば、共通のレイヤーとそれ以外のレイヤー(非共通レイヤー)で分解して使うことで上述のようなケースにおいて処理を軽くすることができます。

たとえばですが、上図のように下位3層のレイヤーにおける重みがモデルABCいずれにとっても共通なのであればここは共通化してしまい、非共通レイヤーのみを推論時にロード・アンロードすることで推論の速度を大きく落とさずにサーバの台数を減らすことが可能 となります。

元のモデル全体をロード・アンロードするのは負荷が大きくなる場合でも、このように非共通レイヤーのみをロード・アンロードする分には大きなパフォーマンス影響を受けずに済む可能性があります。
この例では3台のサーバを1台に集約できているのでコストは1/3になります。
実際弊社のあるプロジェクトではこの方法でコストを80%ほど削減することに成功しました。
まとめ
最近はみんな「L・L・M!L・L・M!」と騒いでいるらしいですが、実際に現場ではこういったパフォーマンスチューニング等を地道に行うことが求められたりもします。
特にTransformerはHuggingFaceのTransformersを使うことで気軽に誰でも機械学習モデルを利用できる反面、なにも考えずに使っていると様々なコスト(単純にモデルがでかくてGPUが必要になったり、今回のように実は共通化できる部分があるのに気づかずに大量に似たようなモデルを並べていたり)が発生しがちかなと思います。
楽に使えるありがたさを実感しつつ、現場では常にコスト最適化してよりよいサービス提供を目指せたらいいなと思う次第です。