
9月だというのに相変わらず暑い日が続きますねえ。
僕は今年も山梨に行けなかったので、なかなか興梠浅間モデルの真相にたどり着けません。
ひなが生きた世界はどんな世界だっただろうと思いながら今日も画面に向かう日々です。
来年の8月こそは山梨にたどり着けるといいんですが……
AWS NeuronがLlama2を正式サポート!
どうも@ken11です。最近はもっぱら後輩の面倒を見たりLLMの動向を見守ることが仕事になっています。
さて、暑い日々が続いておりますがこちらもなかなかホットなようで、弊社でもかねてより愛用しているAWS NeuronがこのたびMeta社のLlama2モデルを正式サポート1しました。2
今回のバージョンアップで、 transformers-neuronx を使った推論と neuronx-nemo-megatron を使った学習の両方がサポートされています。
公開から話題に事欠かないLlama2モデルを、Trn1・Inf2といったコストパフォーマンスに優れた環境3で学習・推論できるということで僕はとても楽しみです。
というわけで今回は早速、Inf2における推論を試していきたいと思います。
Inf2上でLlama2を動かしてみる
なにはともかく実行してみましょう。
実行するといっても、わかりやすいノートブックが用意されているので単純にこれを実行するだけです。
meta-llama-2-13b-sampling.ipynb
サンプルは13Bですが、今回僕は7Bで試してみようと思います。
ノートブックを見てもらえばコードはわかりますし、ここでは簡単に紹介程度にとどめます。
まず対象のモデルを save_pretrained_split を使って分割しておいて
from transformers_neuronx.module import save_pretrained_split save_pretrained_split(model, './Llama-2-7b-split')
分割されたものをNeuronコンパイルして
from transformers_neuronx.llama.model import LlamaForSampling os.environ["NEURON_CC_FLAGS"] = "--model-type=transformer-inference" neuron_model = LlamaForSampling.from_pretrained('./Llama-2-7b-split', batch_size=1, tp_degree=2, amp='f16') neuron_model.to_neuron()
推論するだけです
with torch.inference_mode(): generated_sequences = neuron_model.sample(input_ids, sequence_length=256, top_k=10)
相変わらずとても簡単にAWS Neuronでモデルの推論が実行できることがわかります。
この辺の取っ組みやすさ、移行コストの低さはInf1の時にも感じた部分で、AWS Neuronの魅力だと思っています。
推論速度
では気になる推論速度はどれくらいなのでしょうか?
今回は 英文でサンプルを100個用意し、その推論にかかる時間を計測 しました。
また、このとき重要になる要素としてtensor parallelismの数があります。
Inf2に搭載されているAWS Inferentia2 チップには 1チップあたり2Neuronコア 存在し、1チップ搭載のInf2.xlargeおよびInf2.8xlargeでは2コア、6チップ搭載のInf2.24xlargeでは12コア、それぞれ存在します。
簡単に言ってしまえばこのNeuronコアをどこまで活用して推論を実行するかというのがtensor parallelismで、これは上述のコンパイル処理前に tp_degree という引数で指定することができます。
通常ですと、Inf2.xlargeおよびInf2.8xlargeでは2コアあるので tp_degree=2 になりますし、Inf2.24xlargeでは12コアあるので tp_degree=12 となります。
このtensor parallelism数が与える影響がどの程度なのか、即ちコアをフルに使い果たすのとそうでないのでどれくらい差があるのかといった部分も少し見ていきたいと思います。
そして、特に説明がある場合を除いて以下の結果はすべて sequence_length=256, top_k=10 で実行しています。
Inf2.8xlarge
まず Inf2.8xlarge (1チップ2コア) の tp_degree=2 の結果です。
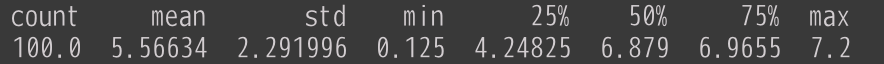
平均で5.5秒程度ということでまあまあでしょうか。
今回 sequence_length=256 とやや短め(?)にしているので早いというのもあると思います。
そして neuron-top コマンドを使って推論時の負荷を見たものがこちらです。
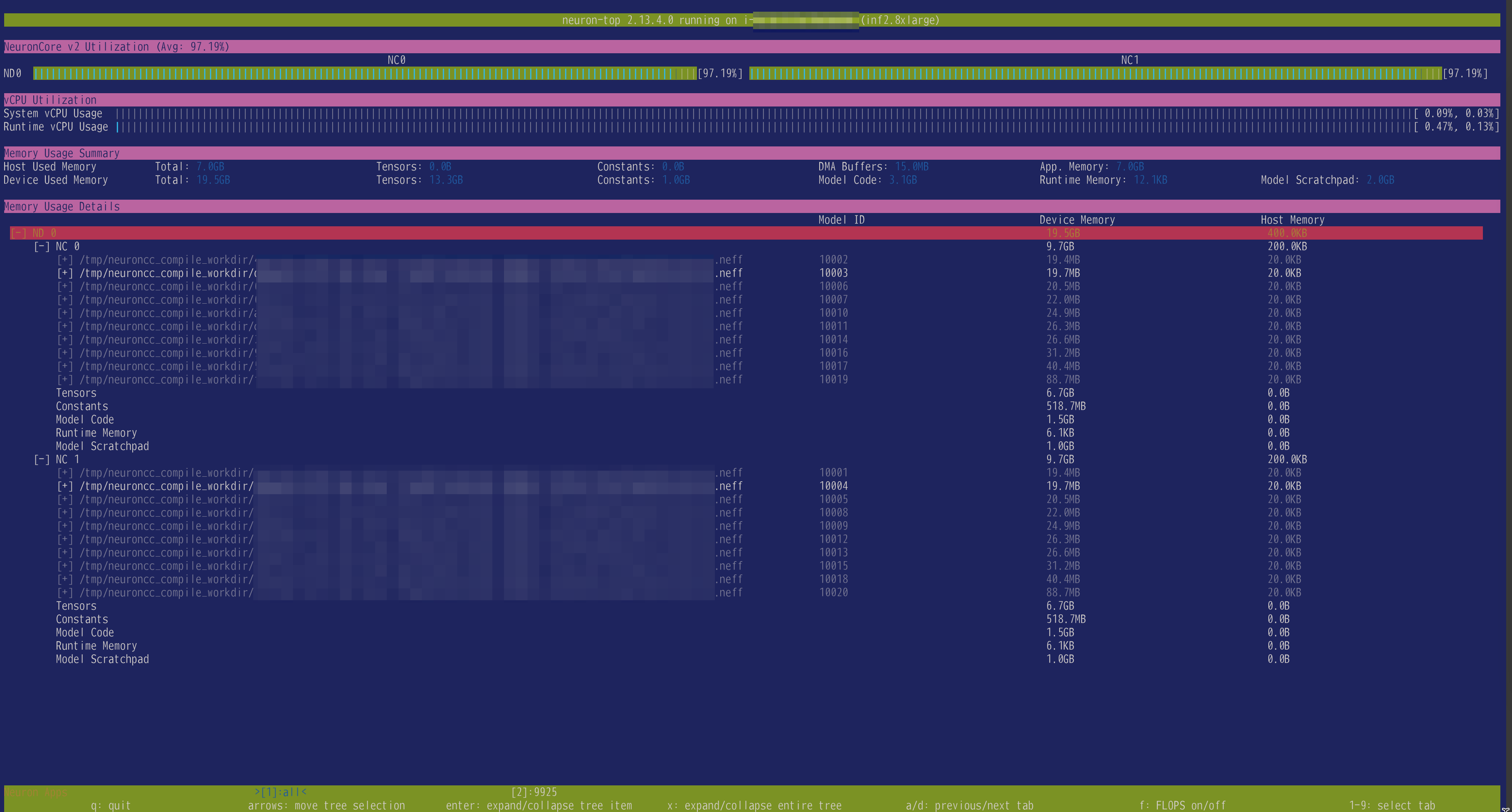
tp_degree=2 を指定しているので、2つあるNeuronコアがどちらも元気に動いていることがわかりますね。
というわけでこの調子でどんどん見ていきましょう。
Inf2.24xlarge
続いて Inf2.24xlarge (6チップ12コア) の tp_degree=12 の結果です。
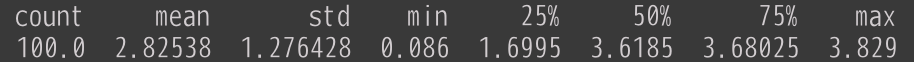
平均で2.8秒程度、8xlの半分くらいになっています。
neuron-top の様子がこちら
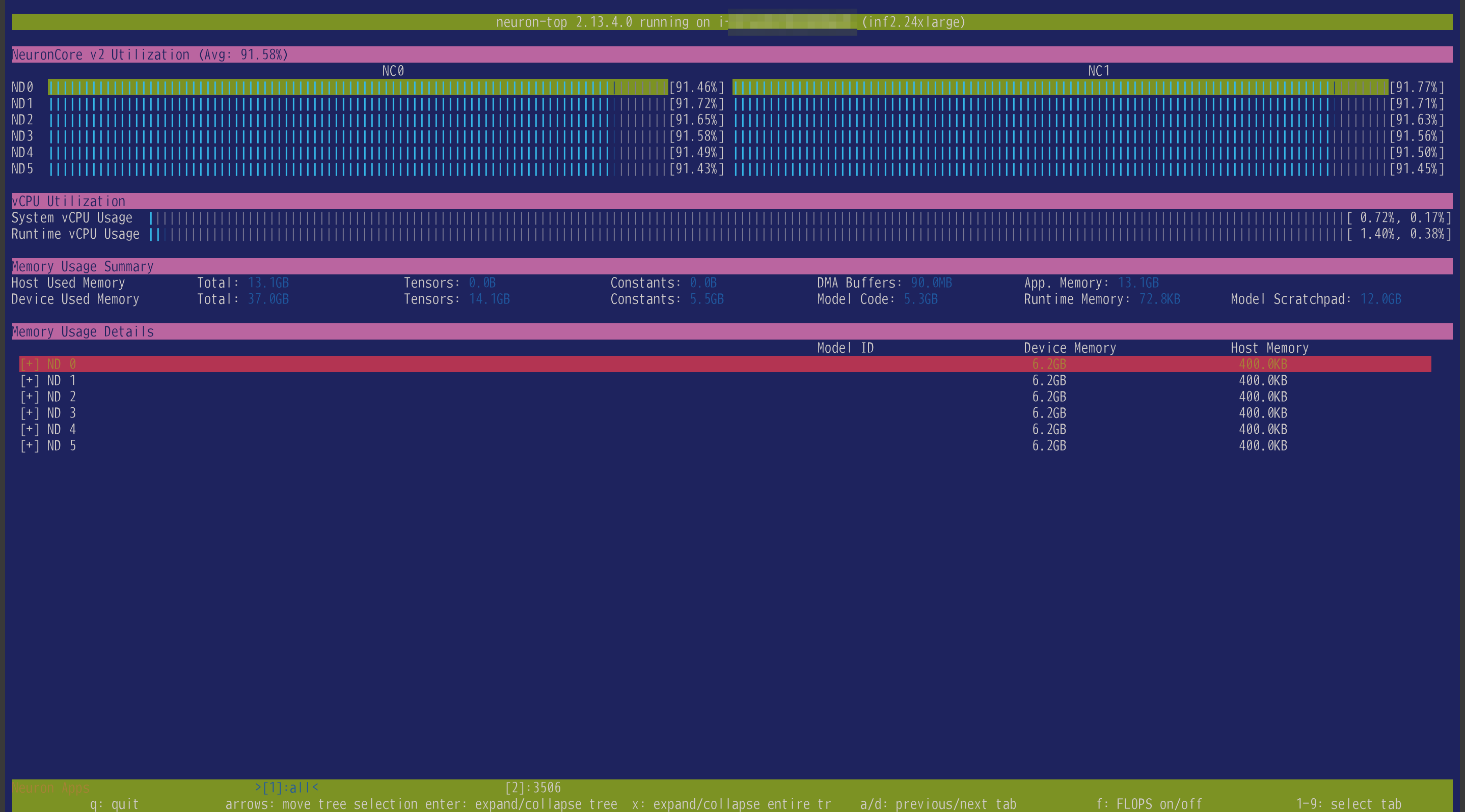
6チップ12コアがフルに動いていることがわかります。
余談ですが ND はNeuron Device即ちチップで NC はNeuron Core即ちコアのことだと思われます。
Inf2.48xlarge
最後に Inf2.48xlarge (12チップ24コア) の結果です。
まず tp_degree=24 の結果です。

平均1.5秒程度、先ほどよりさらに半分くらいになっています。
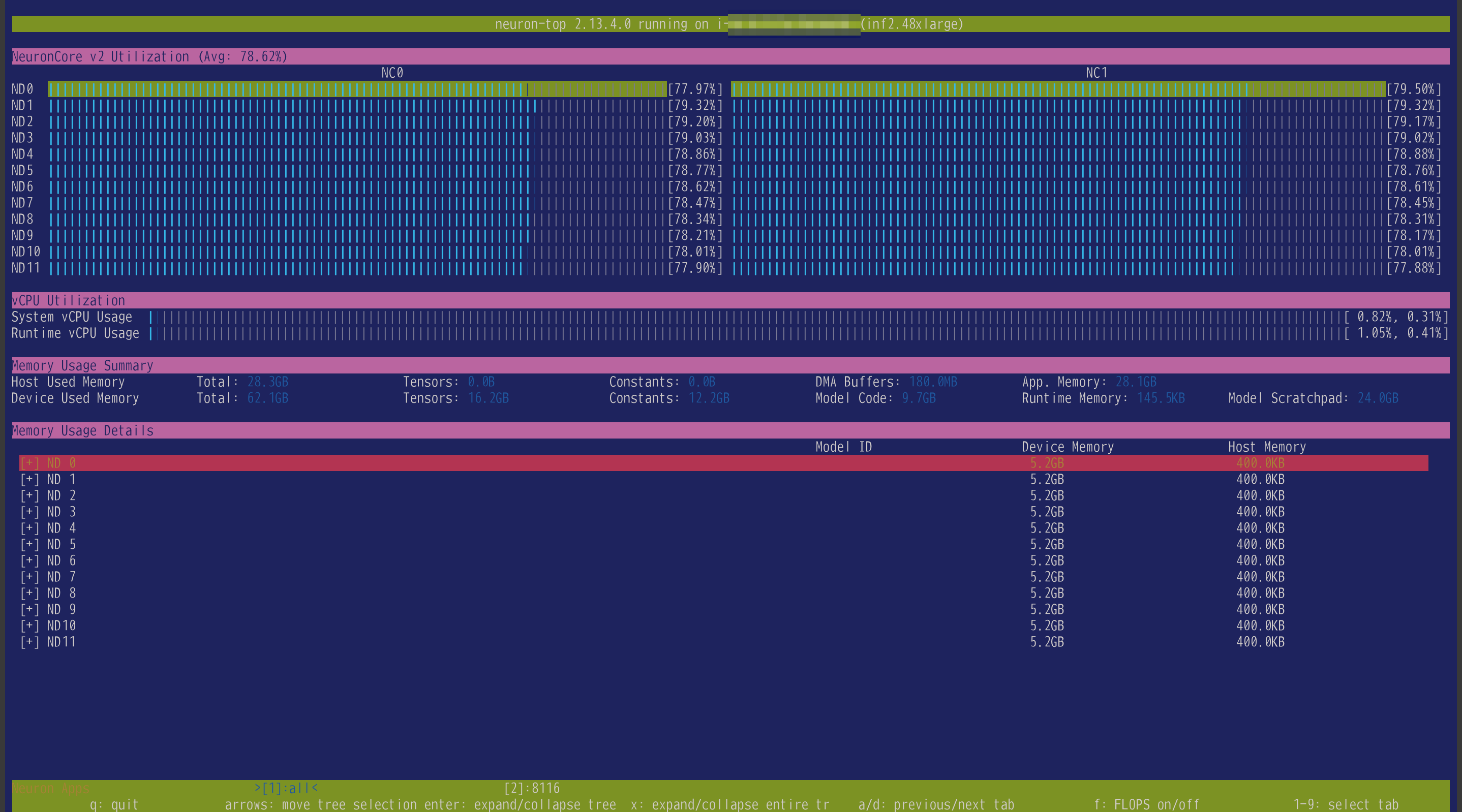
12チップ24コアあると壮観ですね。この様子を見守るのはなかなか綺麗で気持ちがいいです笑
ただ、見てもらうとわかる通り各コアで若干パワーを持て余しているように見えます。(たまたま負荷の低いタイミングだった可能性も否めませんが)
これをどう受け止めればいいのか僕はまだわかっていません。
余力がある分、 tp_degree を減らせばいいのか……?
というわけで減らしてみたのが次の結果です。
tp_degree=12 つまり半分のコアしか使わない設定にしてみました。

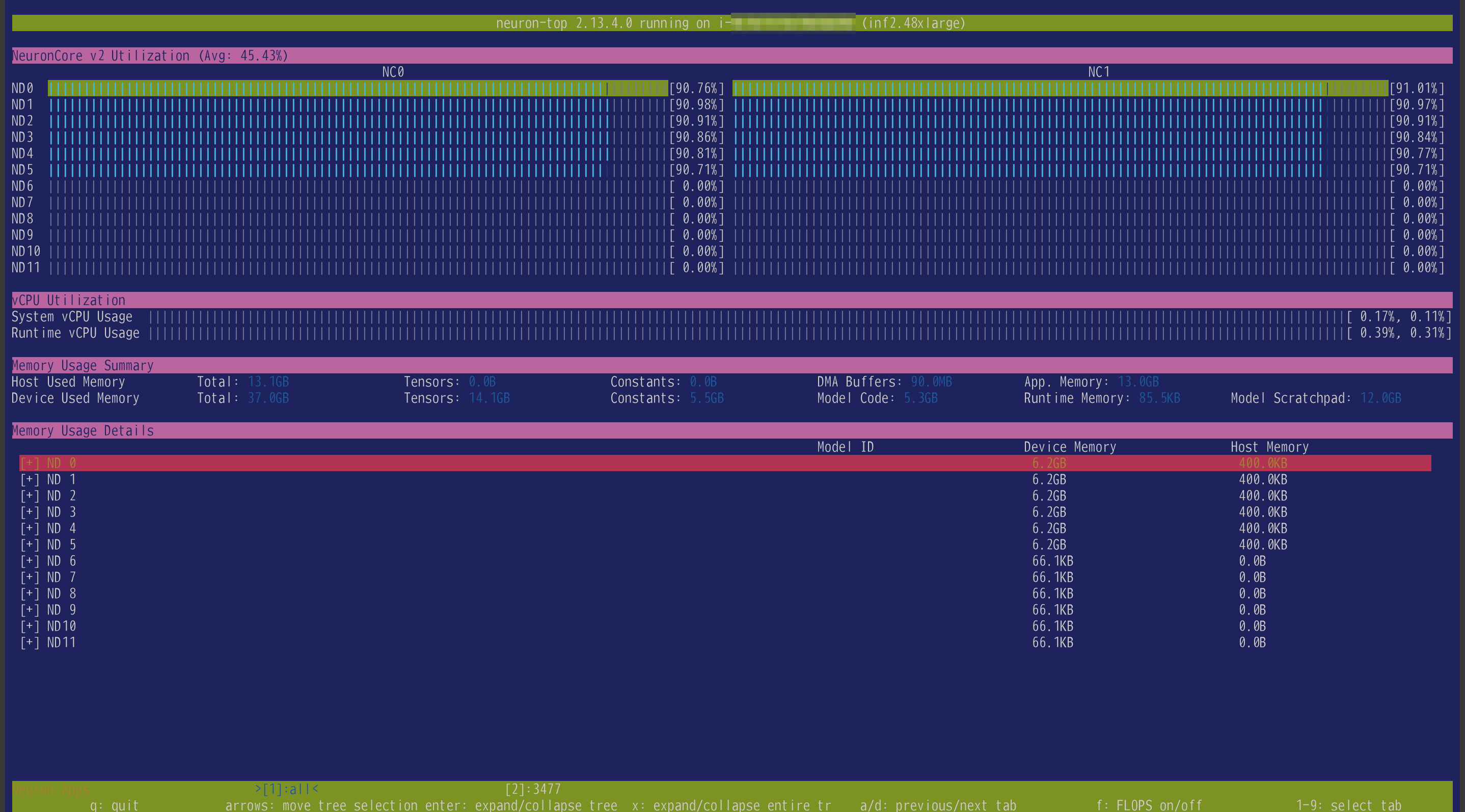
neuron-top の通り、綺麗に半分のコアだけが使われましたが、推論にかかった時間も平均3秒としっかり倍の時間がかかっていました。
こうなるとやはりコアはすべて使い切った方がパフォーマンスはよいのだなということがわかります。(当然ではありますが……)
おまけとして、 sequence_length=2048 にしてみた結果も掲載します。( tp_degree=24 )
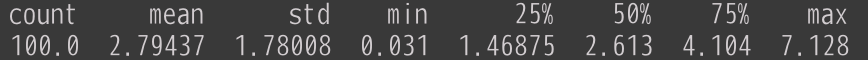
256の時が平均で1.5秒程度だったのに対し今回は平均2.8秒程度ということで、そこまで遅くなっている感じはしません。
ただこれは入力文に対して出力分がどの程度の長さになるのかにも依存しているので、単純に長文でも早いということを示しているわけではありません。
それを考えるには、確実に出力が長くなるであろう入力文を入れるなど、もう少し丁寧な調査が必要となります。今回はそこまではしていないので、参考値でしかないですね。
実測結果を受けて
推論の実行自体は以上のような結果で、正確にGPUでの推論と比較はしていませんが体感では早くなっているなと感じる次第です。
Inf2.8xlargeであればオレゴンでUSD 1.96786/hourほどの料金となっています。
1ヶ月732時間で1台当たり1500ドルかからないくらいなので、高速な推論を求められる環境でなければLlama2-7Bを自分でホスティングする可能性も十分考えられるんだなということがわかりました。
様々なLLMが登場してきている状況ですが、実際に動かそうとするとやはりコストが気になるところなので、Inf2のようなインスタンスで実行可能になっていくと選択肢も増えてとても助かるなと思う次第です。
キャッシュについて
せっかくなので最後に少しだけ小ネタを話しておこうかと思います。
v2.13.0からNeuron Persistent Cacheという仕組みが実装されました。
これにより、コンパイルした結果がキャッシュされるようになります。
キャッシュされるので、2回目以降はコンパイルが発生しないという利点があります。
デフォルトではキャッシュの保存先は /var/tmp/neuron-compile-cache となっているのですが、実は保存先のパスは
os.environ["NEURONX_DUMP_TO"] = "./compiler_cache"
といった感じに指定すれば変えられるという情報をAWSからいただきました!
実際に保存先変更を試してみたところ問題なく動きましたが、なぜかコンパイル時にログが流れるようになったので、ログレベルが一緒に変わってしまうのかも?とちょっと思いました。(ここはまだ詳しいことはわかっていない)
明示的にキャッシュの保存先を変えたい方はどうぞ。
まとめ
今回はAWS NeuronがLlama2を正式サポートしたということで早速Inf2インスタンス上でLlama2を動かしてみました。
Llama2は既に各社ファインチューニングなど取り組まれていて話題になっている通り、使い勝手のよさなども魅力だと個人的に感じています。
そんなLlama2がAWS Neuronで、Inf2/Trn1を使って推論や学習ができるのは可能性が広がってとても面白いなと感じています。
僕もいろいろ試しながら使い倒していきたいと思います!
- https://awsdocs-neuron.readthedocs-hosted.com/en/latest/release-notes/index.html#neuron-2-13-1-08-29-2023↩
- ちなみに今だと13Bまでらしいです、70Bは正式対応ではないという話↩
- 僕が今まで触ってきたレベルでは概ねサポートされているモデルについてはコストパフォーマンスの向上を確認しています。もちろん一概にすべてのユースケースとは言えないのであくまで僕が見てきた範囲では、の話。↩