
はじめに
あけましておめでとうございます。k0iです。 皆さんは年末年始、いかがお過ごしでしたでしょうか。
私は久しぶりに会った高校の友達と飲んで帰省の列車に乗り遅れ、更にスマホを落として壊してしまい中々痺れる年越しとなりました。
2024年も良い年になると良いですね.....!
さて、Rails 7.1 で trilogy という MySQL 互換の Database Adapter が追加されました。
しかし我々はすでに MySQL 互換の Database Adapter として mysql2 を使っています。
一体なぜ新しい Adapter が必要なのか。trilogy は何を解決するために開発されたのか。
気になりませんか?(なりますよね?)
そこで、trilogy について開発の背景や、採用すると何が嬉しいのかを調査してみました。
タイトルにもある通り、調査の過程で Active Record が抱える問題(#42271)についても学べたので、 その内容も含めておおまかにまとめてみました。
目次
- trilogy とは? なぜ新しい Adapter が必要なのか
- mysql2 の問題点
- trilogy コードを実際に追う
- 実際に Fiber で trilogy を使ってみる
- 現状の Active Record の問題点と Fiber を使う意義
- さいごに
TL;DR
- trilogy は libmysqlclient への依存を無くし、非同期 API を提供することで mysql2 が抱えていた問題を解決している
- trilogy は現状内部で rb_wait_for_single_fd を呼ぶことで非同期処理を実現している
- また、trilogy は FiberScheduler にも対応している
- Fiber を使うことで パフォーマンスの向上が期待できる
- 現状の Active Record は request の開始から終了まで DB Connection を占有しているが、Fiber を使うことで DB Connection の効率的な利用が可能になるかもしれない
1. trilogy とは? なぜ新しい Adapter が必要なのか
trilogyはご存知の通り、 MySQL compatible な Database Adapter です。
しかし Rails にはすでに MySQL compatible な Adapter として mysql2 がありますよね。 なぜ今になって新しい MySQL compatible な Adapter が必要なのでしょうか。
その背景には mysql2 が抱えている問題がありました。
mysql2 の問題点
(この章はほぼこのissueに書かれていることを軽くまとめたものです。)
mysql2 には大きく分けて 2つの問題点がありました。
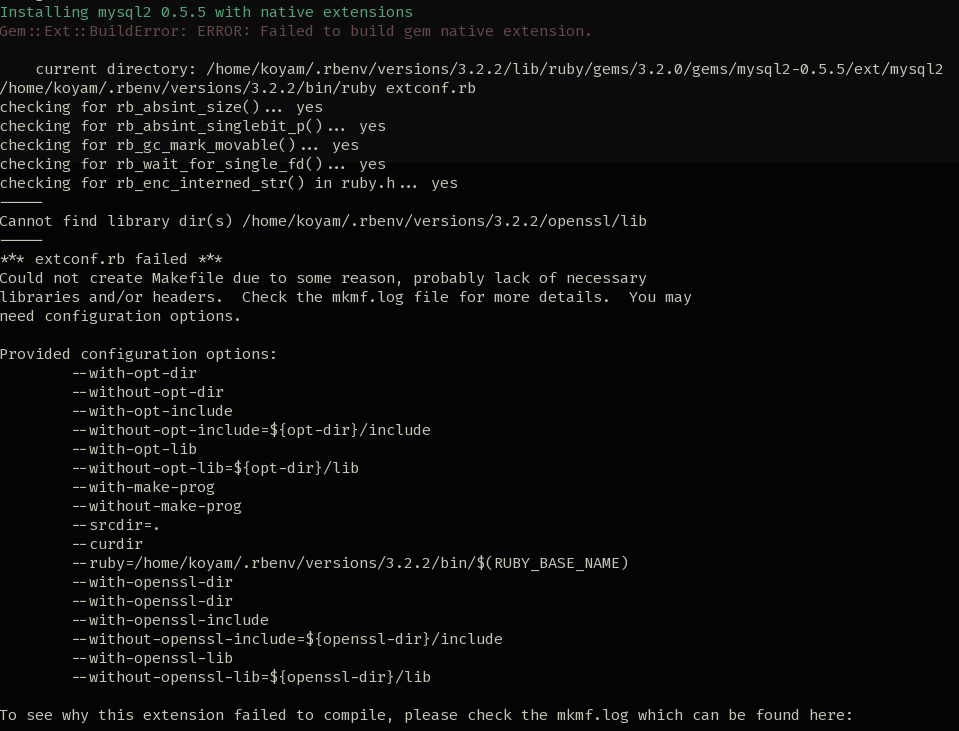
1つ目は libmysqlclient への依存です。mysql2 gem を build する際にエラーに遭遇した経験がある方も多いのではないでしょうか。
2つ目は非同期 API がわかりにくいということです。 libmysqlclient は API document を見る限りは非同期 API を提供していません。
しかし実は document に載っていない「関数」を使うことで非同期処理を実現すること自体は一応可能です。
libmysqlclient がそういった不透明な状態であるため、その binding である mysql2 も非同期 API を現状提供していません。
trilogy は mysql2 が抱えていたこれら 2つの問題点を解決するために開発された、ということらしいですね。 個人的には mysql2 のインストールでいつもやらかしていたので、そこが解決されているのは非常に嬉しいです。
2. trilogy コードを実際に追う
先ほど開発背景を調べましたが、急に「非同期処理ができるようになった」と言われると中で何をやっているのか気になりますよね。 コードを実際に追ってみましょう。
例として、簡単そうなActiveRecord::Base.connetion.executeを実行した際の処理を追ってみます。
ActiveRecord::Base.connection.execute は最終的にTrilogyAdapter.new_clientで生成されたTrilogy class
のインスタンスに対してTrilogy#queryを呼び出します。
(Active Record の中も色々載せたいのですが、かなり長くなってしまうので,今回は省略します。)
module ConnectionAdapters class TrilogyAdapter < ::ActiveRecord::ConnectionAdapters::AbstractMysqlAdapter class << self # このメソッドで返された値(::Trilogy.new)に対して#query が呼び出される def new_client(config) config[:ssl_mode] = parse_ssl_mode(config[:ssl_mode]) if config[:ssl_mode] ::Trilogy.new(config) rescue ::Trilogy::ConnectionError, ::Trilogy::ProtocolError => error raise translate_connect_error(config, error) end ...
trilogy gem の#queryが呼ばれることが分かったので、ここから trilogy の内部を見ていきます。
#queryの実体はrb_define_method(Trilogy, "query", rb_trilogy_query, 1);で定義されているrb_trilogy_queryです。
早速rb_trilogy_queryから追っていきます。
static VALUE rb_trilogy_query(VALUE self, VALUE query) { struct trilogy_ctx *ctx = get_open_ctx(self); StringValue(query); query = rb_str_export_to_enc(query, rb_to_encoding(ctx->encoding)); int rc = trilogy_query_send(&ctx->conn, RSTRING_PTR(query), RSTRING_LEN(query)); // client.hの定義 // TRILOGY_AGAIN - The socket wasn't ready for writing. The caller should // wait for writeability using `conn->sock`. Then call trilogy_flush_writes. if (rc == TRILOGY_AGAIN) { rc = flush_writes(ctx); } if (rc < 0) { handle_trilogy_error(ctx, rc, "trilogy_query_send"); return execute_read_query_response(ctx); }
trilogy_query_sendの返り値としてTRILOGY_AGAINという気になる定数が出てきました。これはなんでしょう.....
client.h には
TRILOGY_AGAINが返却された場合、呼出側はconn->sockを使って書き込み可能になるまで待ち、trilogy_flush_writesを呼び出す必要があります。
のようなことが書かれています。
なのでTRILOGY_AGAINが返された場合に呼ばれるflush_writesは、説明どおり通り書き込み可能になるまで待って、trilogy_flush_writesを呼び出す処理を行っているのだと思います。
確認してみましょう。
static int flush_writes(struct trilogy_ctx *ctx) { while (1) { int rc = trilogy_flush_writes(&ctx->conn); if (rc != TRILOGY_AGAIN) { return rc; } rc = trilogy_sock_wait_write(ctx->conn.socket); if (rc != TRILOGY_OK) { return rc; } } }
最初に再度trilogy_flush_writesを呼び出してはいますが、
確かにその後trilogy_sock_wait_writeといういかにも「書き込み可能になるまで待ち」そうな関数を呼び出していますね。
trilogy_sock_wait_writeは単に socket->wait_cbにTRILOGY_WAIT_WRITEを渡して呼び出すのみです。
static inline int trilogy_sock_wait_write(trilogy_sock_t *sock) { return sock->wait_cb(sock, TRILOGY_WAIT_WRITE); }
そしてsock->wait_cbの実態は_cb_ruby_waitであり、最終的に Ruby のrb_io_waitを呼び出しています。
VALUE rb_io_wait(VALUE io, VALUE events, VALUE timeout) { VALUE scheduler = rb_fiber_scheduler_current(); if (scheduler != Qnil) { return rb_fiber_scheduler_io_wait(scheduler, io, events, timeout); } rb_io_t * fptr = NULL; RB_IO_POINTER(io, fptr); struct timeval tv_storage; struct timeval *tv = NULL; if (NIL_OR_UNDEF_P(timeout)) { timeout = fptr->timeout; } if (timeout != Qnil) { tv_storage = rb_time_interval(timeout); v = &tv_storage; } int ready = rb_thread_wait_for_single_fd(fptr->fd, RB_NUM2INT(events), tv); if (ready < 0) { rb_sys_fail(0); } // Not sure if this is necessary: rb_io_check_closed(fptr); if (ready) { return RB_INT2NUM(ready); } else { return Qfalse; } }
真ん中あたりでrb_thread_wait_for_single_fdが呼び出されていますね。
rb_thread_wait_for_single_fdは一つの fd に対して渡された events(今回はRB_WAITFD_OUTという書き込み可能かどうかを表す定数)が発生するのをppollで待ちます。
なので総括すると、
ActiveRecord::Base.connection.executeが呼び出されると、
Trilogy#queryが呼び出されるTrilogy#query中でtrilogy_query_sendを呼び出すTRILOGY_AGAINが返された場合はrb_thread_wait_for_single_fdを呼び出しppollで書き込み可能になるまで待ち、他スレッドに処理を譲る
ということをしているようです。
(ppollが定義されていない場合は....select などの何かしらの syscall を呼び出しているのだと思いますが、ここまで追えばとりあえずやってることは分かったので、調査を終了します。)
rb_io_waitには thread の他にもう一つ気になる点がありました。
FiberSchedulerが登録されている場合はrb_fiber_scheduler_io_waitを呼び出している点です。
Fiber単位での非同期処理もできるようになっているみたいですね......!
3. 実際に Fiber で trilogy を使ってみる
前述の通り、trilogy は非同期処理を実現するためにrb_thread_wait_for_single_fd、またはrb_fiber_scheduler_io_waitを呼び出しています。
なので、trilogy を使うことで thread はもちろん、Fiber 単位での非同期処理も実現できるようになっているように見えます。 thread と比較して生成コストや context switch のコストが低い Fiber を使うことで、パフォーマンスの向上が期待できそうです。 実際に試してみましょう。
Sync do 5.times.map do Async do ActiveRecord::Base.connection.execute('do sleep(1);') end end.map(&:wait) end
1秒 SLEEP するクエリを 5つ非同期で実行してみます。 もし本当に非同期で実行されているのであれば、レスポンスは 1秒かそこらで返ってくるはずです。
なんだかドキドキしますね。早速リクエストを投げてみます。
ab -n 500 -c 5 -u put.json http://0.0.0.0:3000/accounts/1/
結果は..............
残念ながら TRILOGY_INVALID_SEQUENCE_IDエラーが出て segmentation fault してしまいました。
... "severity":"warn","oid":26080,"pid":171398,"subject":"Async::Task","message":["Task may have ended with unhandled exception.","Trilogy::QueryError: trilogy_query_recv: TRILOGY_INVALID_SEQUENCE_ID"], ... /home/koyam/.rbenv/versions/debug/lib/ruby/gems/3.3.0+0/gems/activerecord-7.1.2/lib/active_record/connection_adapters/trilogy/database_statements.rb:48: [BUG] Segmentation fault at 0x0000000000000008 ruby 3.3.0dev (2023-10-05T04:19:09Z master a472fd55da) [x86_64-linux] ...
結局、trilogy では Fiber 単位での非同期処理を実現できないのでしょうか....?
前述のエラー原因を知るためには、Rails がどのように DB Connection を扱っているのかを知る必要があります。
詳しくはこちらの記事にまとまっているのですが、
Active Support にはIsolatedExecutionStateというモジュールがあり、その中で定義されているself.isolation_levelはデフォルトで:thread になっています。
ConnectionPoolクラス内ではこの isolation_level 単位でconnectionを管理しています。
つまるところ isolation_level が :threadであるというのは DB connection が Thread 単位で管理されるということを意味します。
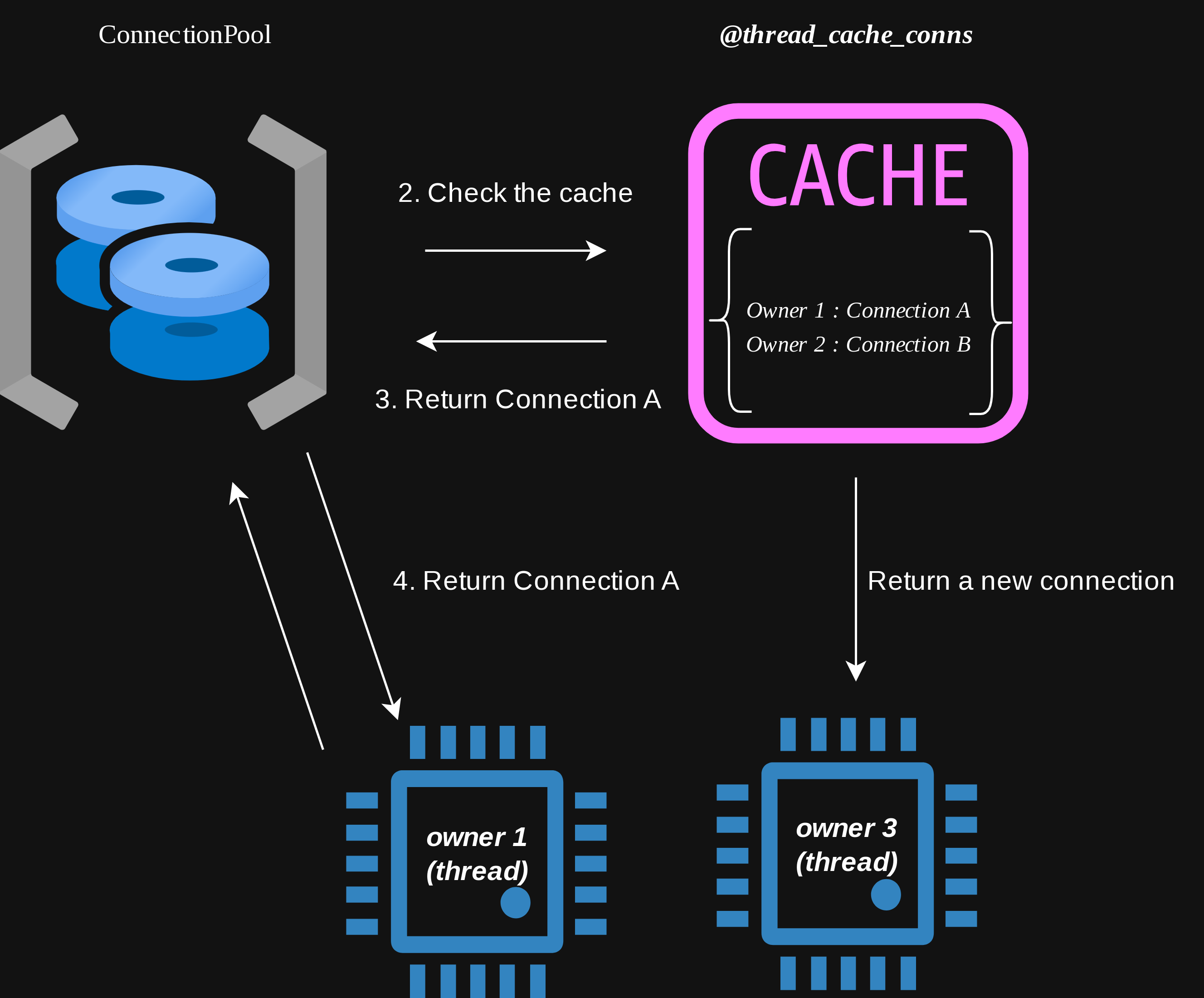
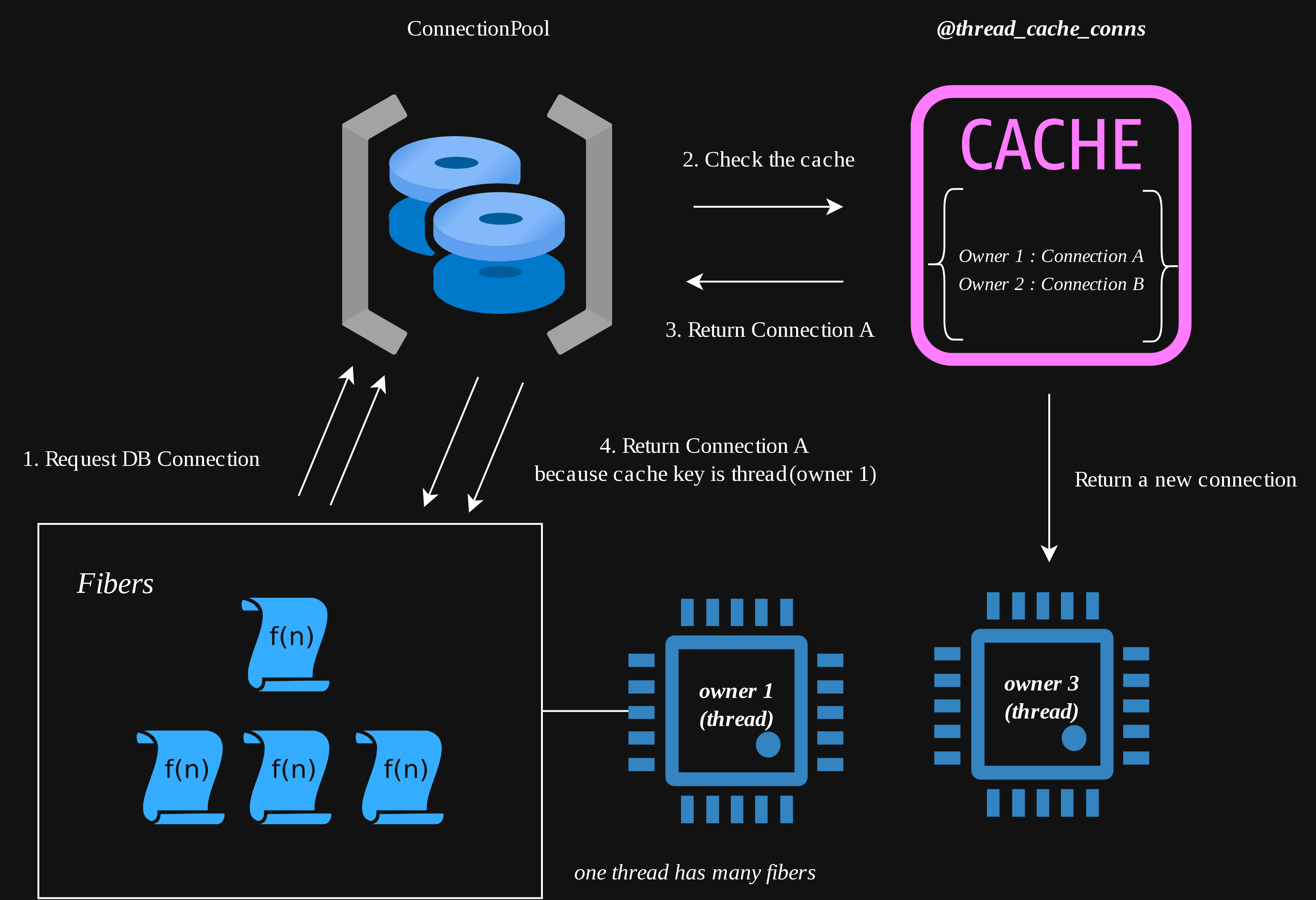
ここで 1Thread に対して複数存在できる Fiber が 同様に Connection Pool に問い合わせた場合、 DB Connection が Thread 単位で管理されているため、同じ DB Connection を取得することになります。
その結果上のエラーが発生することになります。
この isolation_level はconfig.active_support.isolation_levelによって変更することができます。
実際、config.active_support.isolation_level = :fiber に変更すると、 segmentation fault は発生しなくなります。
しかし公式ドキュメントには Fiber ベースのサーバーを使うときなどに isolation_level を変更するよう書かれています。
残念......結局 Puma などの Thread ベースのサーバーを使う場合は結局 Fiber は使えないのでしょうか。(この流れ 2回目)
実はActiveRecord::Base.connection_pool.checkout/checkinすることで、
新しい connection を獲得でき、結果的に Fiber 単位で DB Connection を取得することができます。
Sync do 5.times.map do Async do connection = ActiveRecord::Base.connection_pool.checkout connection.execute('do sleep(1);') ensure ActiveRecord::Base.connection_pool.checkin(connection) end end.map(&:wait) end
Started PUT "/accounts/1/" for 127.0.0.1 at 2024-01-03 16:24:51 +0300
Processing by AccountsController#update as */*
Parameters: {"id"=>"1"}
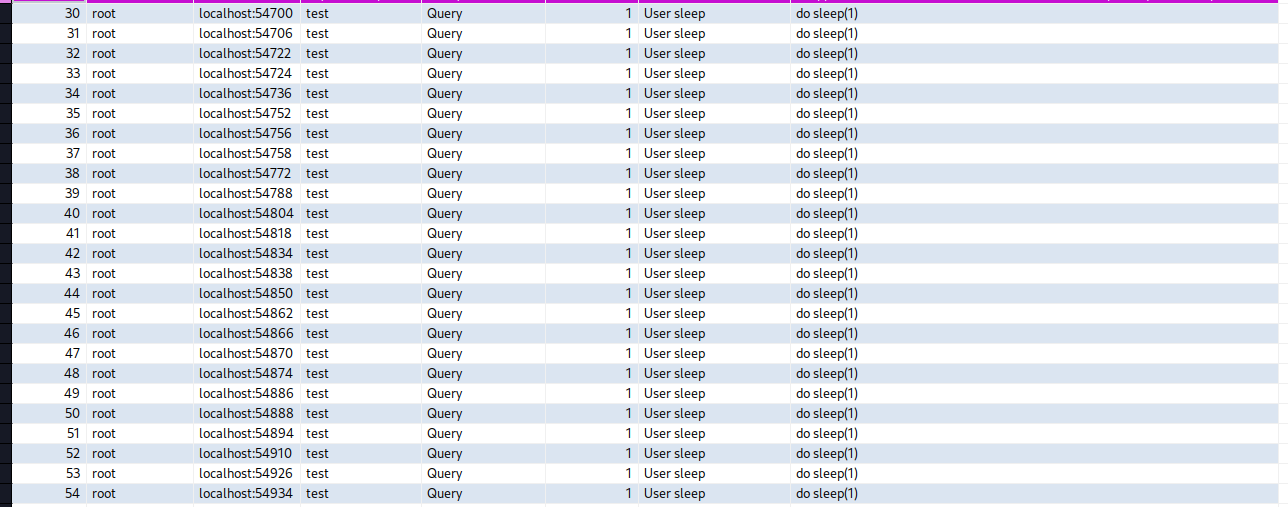
(1000.8ms) do sleep(1);
↳ app/controllers/accounts_controller.rb:32:in `block (3 levels) in update'
(1001.5ms) do sleep(1);
↳ app/controllers/accounts_controller.rb:32:in `block (3 levels) in update'
(1001.9ms) do sleep(1);
↳ app/controllers/accounts_controller.rb:32:in `block (3 levels) in update'
(1002.2ms) do sleep(1);
↳ app/controllers/accounts_controller.rb:32:in `block (3 levels) in update'
(1002.6ms) do sleep(1);
↳ app/controllers/accounts_controller.rb:32:in `block (3 levels) in update'
Redirected to http://0.0.0.0:3000/accounts/1
Completed 302 Found in 1005ms (ActiveRecord: 5009.0ms | Allocations: 1754)
# 5回SLEEPしているが処理終了までかかったのはおよそ1秒
やった~ 🎉
一点注意ですが、Puma の Worker数 × Thread数 × Fiber数 の DB Connection が必要になるので、
不用意に Fiber を使うと DB Connection の枯渇を招く可能性があります。
(これについては Thread 立てて DB Connection を獲得している load_async なども同様ですが..)
4. 現状の Active Record の問題点と Fiber を使う意義
ここまででなんとか Fiber 単位での非同期処理を実現することができました。
しかし喜びもつかの間、よく考えてみると今や Rails にはload_asyncなどの非同期処理を実現するためのメソッドが用意されています。
Fiber を使う意義はあるのでしょうか。
1つ目のポイントとして、前述した通り Thread と比較したときの生成コストや context switch のコストが低いことが挙げられます。
現状load_asyncなどは Thread を生成して非同期処理を実現していますが、OS Thread と Ruby Thread は 1:1 で対応しているため、
やはり Thread の生成コストは無視できないと思います。
適当に手元でとったベンチマークなのであまり信用できませんが、Thread と 比較するとやはり Fiber の方が断然生成コストが低いです。
Calculating -------------------------------------
thread_1 25.407k (±54.0%) i/s - 227.691k in 10.139172s
fiber_1 754.876k (± 0.6%) i/s - 7.565M in 10.022495s
thread_10 9.119k (±12.4%) i/s - 89.748k in 10.082345s
fiber_10 109.353k (± 0.4%) i/s - 1.097M in 10.032785s
thread_100 1.127k (± 6.7%) i/s - 11.277k in 10.055552s
fiber_100 11.612k (± 0.6%) i/s - 116.270k in 10.013381s
thread_1000 37.597 (± 5.3%) i/s - 378.000 in 10.071614s
fiber_1000 1.144k (± 3.2%) i/s - 11.448k in 10.014251s
もし load_async などが Fiber を使って実現できるようになれば、パフォーマンスの向上が期待できるかもしれません。
2 つ目のポイントとして、将来的な話になりますが、Fiber を使う理由と Active Record が抱える問題が深く関わってきます。 (ここから先の内容はこの issueに書かれていることを自分なりにまとめたものです。)
現状の Active Record は request 内で connection を獲得した場合、その request が終了するまで DB Connection を占有します。 これは
with_connectionといった block を明示的に使わなくてもModel.findなどを呼び出せば自動的に connection を獲得してくれる- Rack middleware によって connection が pool に戻されるので、ユーザーは connection 管理を意識する必要がない
というメリットがある一方、DB Connection を占有する時間が長くなるというデメリットがあります。 つまり、query の所要時間が 1ms であっても、request の所要時間が 1s であれば、DB Connection は 1s 間占有されてしまいます。
もし Thread よりも生成コストがかからない Fiber を使って、
- database query が発生したら都度 Fiber を生成し DB Connection を獲得
- database query が終了したら 即座に Connection を Pool に戻す
ということが実現できるようになれば、DB Connection をより効率的に使うことができるようになります。
Puma の Worker 数 × Thread 数 より小さい数の DB Connection でもリクエストを十分に処理できるようになるかもしれません。
もしかしたら Reaper Thread の必要性もなくなるかもしれませんね!(あくまで個人的な予想です)
5. さいごに
今回は Rails 7.1 で追加された trilogy について調査してみました。 その過程で Rails の内部をより深く知ることができ、また Active Record が抱える問題についても学ぶことができました。
Ruby3.3 で M:N Scheduler が実装されるということで、また色々と変更がありそうですが、 Ruby のバージョンアップ作業と合わせて、trilogy の導入も適宜検討していきたいと思います。
最後まで読んでいただきありがとうございました。
私の所属するMoneyforward 福岡開発拠点では一緒に働く仲間を募集しています! ご興味ある方は是非一度こちらをご覧ください!