
What is this blog for
The main purpose of this blog series is to encourage and support creating ML models on edge devices in our company. I've tried my best to make the code and explanations as easy to grasp as possible. Feel free to ask if you have any questions.
This blog series demonstrates my initial experience with ggml, a tensor library for machine learning ("ML" for short). It consists of several parts:
- Part I (this post): Demonstrates a PoC of using the
ggmlframework to execute a forward pass on a lightweight model. - Part II (coming soon): Covers running complete text generation with a larger LLM.
- Part III (coming later): Includes implementation examples not only for LLM but also for other types of models.
The source code has been uploaded to this repository, includes a straightforward ML model inference that involves:
- Rinna's
japanese-gpt-neox-smallmodel: lightweight Japanese LLM, suitable for demonstration purposes. ggml: a feature-rich tensor library for ML, the central topic of this blog post.Ziglanguage: general-purpose programming language, known for its capability to write efficient low-level code and seamless interaction with C.
What is ggml
The primary focus of this post is to introduce the ggml library: it is a tensor library for ML to enable large models and high performance on commodity hardware with the following features:
- Written in C
- Automatic differentiation
- Supports 16-bit float support and integer quantization (e.g. 4-bit, 5-bit, 8-bit)
- Supports WebAssembly and WASM SIMD
- No third-party dependencies
- Zero memory allocations during runtime
Here is a short voice command detection example on a Raspberry Pi 4 using ggmml:
General purpose, short voice command detection on Raspberry Pi 4 using whisper.cpp
— Georgi Gerganov (@ggerganov) December 13, 2022
Supports 100 languages pic.twitter.com/1dlV4kQKNk
Use cases
- Cross-platform compatibility:
ggmlis written in C and equipped with automatic differentiation, making it well-suited for model training and inference in cross-platform applications. It seamlessly operates across various platforms, including Mac, Windows, Linux, iOS, Android, web browsers, and even Raspberry Pi. - Edge computing:
ggmlis designed with a feature that ensures no memory allocation during runtime. It also supports half-size float and integer quantization, allows developers to have better control over memory usage and performance management. This is crucial for making ML models work well on edge devices where efficient resource use is important.
Pros
Compared to other ML inference frameworks such as TensorFlow Lite or ONNX Runtime, ggml offers many benefits:
- TensorFlow Lite is a good solution for executing ML models on mobile and embedded devices. However, it has certain limitations, such as the lack of Windows support. In contrast, ggml supports Windows and even offers integer quantization of 4-bit and 5-bit, broadening its range of potential use cases.
- While ONNX Runtime is another approach which is compatible with many platforms, it requires you to export your model to the ONNX format first. Conversely, ggml doesn't require a specific format for the model file. This means you can convert the model file from any other framework (like TensorFlow, Pytorch, etc.) into a binary file in any format that's easy for you to handle later.
Cons
Certainly, ggml has several areas that require improvement:
- It is still in the development phase and currently lacks comprehensive documentation, which can make it hard for new users to start using it quickly.
- Reusing the source code across different models can be difficult due to the unique structure of each model. At present,
ggmldoes not provide a universal guide for this. Consequently, users often need to create their own inference code, particularly when working with custom models developed in-house. This process requires a deep understanding of how to work with mathematical matrices and the structure of ML models.
Why chose ggml
ggmlhas gained a lot of interest from the open-source community. They've accomplished some impressive works, such as running an LLM as an iOS app. The source code for this project can be found here.
- There are various versions of well-known ML models available with
ggml, likellama.cpp,whisper.cpp,clip.cpp,stable-diffusion.cpp. These resources can be very helpful for beginners looking for guidance. ggmlis a lightweight framework. Its core implementation is neatly organized into a single.cfile, and it doesn't rely on any third-party packages. This makes it straightforward to read the source code and even contribute to it.- Although
ggmlis well-known for its implementation of LLM, its potential is not limited to LLM. It's versatile enough to accommodate other ML models with diverse structures.
Why chose Zig
In addition to ggml, I have also chose Zig, a relatively new programming language compared to C, for developing this project due to the following reasons:
- Zig is a low-level system programming language, praised as an alternative to C. It delivers high performance and includes many beneficial features found in modern languages.
- Zig has become more popular in the community recently because of
bun.sh, a toolkit for JavaScript and TypeScript apps. But it seems that not many people have tried using Zig withggmlyet, so I want to be one of the first to give it a shot.
How to implement model inference using ggml
I've only finished the first step for the easiest example. The entire process of generating text is still being worked on, and I'll explain it more in Part II. If you want to know what I have done, you can check the test code, which demonstrates that it can achieve the same results as the Python version, (i.e. taking the input text "こんにちは、猫は好きですか?" and producing the next token with id of 8, which has the highest logit value).
It's difficult to provide all the detailed explanations in this blog post, so I encourage everyone to explore the source code on their own. I've included some guides and tips here that I believe are the most important.
Convert the origin model file
We need a model file to read the weights, but these models are typically trained using ML frameworks like PyTorch or Jax and can't be directly read using pure C. ggml offers some scripts for converting a PyTorch model file into a specific format for this task, but you can also do it manually because it's relatively straightforward.
You can find an example of model conversion here. Running this script will also create a JSON file containing the model's architecture, like this.
Select a reliable reference sources
When it comes to reading the weights and performing inference, starting from scratch can be quite difficult. This is because you must carefully map each byte from the binary model file to memory tensors, and then perform numerous mathematical operations on them. A single small mistake can result in significant calculation errors later on, rendering the entire process's outputs meaningless.
To prevent this, you can pick good sources to learn code from. These sources can include the original PyTorch model code or the ggml version implemented in C. In the context of this post, when using the Rinna model, which shares the same architecture as GPT-NeoX, you can find the reference sources here and here.
Implement the inference
Now that we have a binary model file containing model weights and a JSON file storing dimensional information for every layer in our model, we can proceed to the main task: reading the model weights and using them for running inference. You can find the sample code in the Zig model file. Here are some tips that I found helpful while working with ggml in Zig:
Compiling
ggmlwith Zig requires adding theggmlsource files to the project and linking withlibc. This can be accomplished by adding these lines to thebuild.zigfile.exe.addIncludePath(.{ .path = "./ggml/include" }); exe.addIncludePath(.{ .path = "./ggml/include/ggml" }); exe.addCSourceFiles(&.{"./ggml/src/ggml.c"}, &.{"-std=c11"}); exe.linkLibC();After that, you can import the functions from
ggmland seamlessly integrate them with other Zig code:pub const ggml = @cImport({ @cInclude("ggml/ggml.h"); });Keep checking the dimensions of tensors stored in the
nefield to ensure that you are on the right track while performing mathematical calculations:std.debug.print("{any}\n", .{tensor.*.ne});ggmldoesn't run the computation immediately, instead it's necessary to build the computational graph before running the forward pass. You can do this by calling these functions:const gf = ggml.ggml_new_graph(context); ggml.ggml_build_forward_expand(gf, lm_logits); ggml.ggml_graph_compute_with_ctx(context, gf, n_threads);
Debugging Python code
Although there are helpful reference resources available, it's important to write most of the code ourselves to fully grasp the model's structure and optimize memory usage effectively. There are also situations when we want to inspect the values of tensors to ensure the accuracy of our calculations.
In my case, I was using ggml with Zig, and it was necessary for me to consistently compare the values of elements in each tensor in my implementation with the original Python code to ensure they are the same. You can easily examine the values of tensors using handy debugging tools in VS Code, like this:
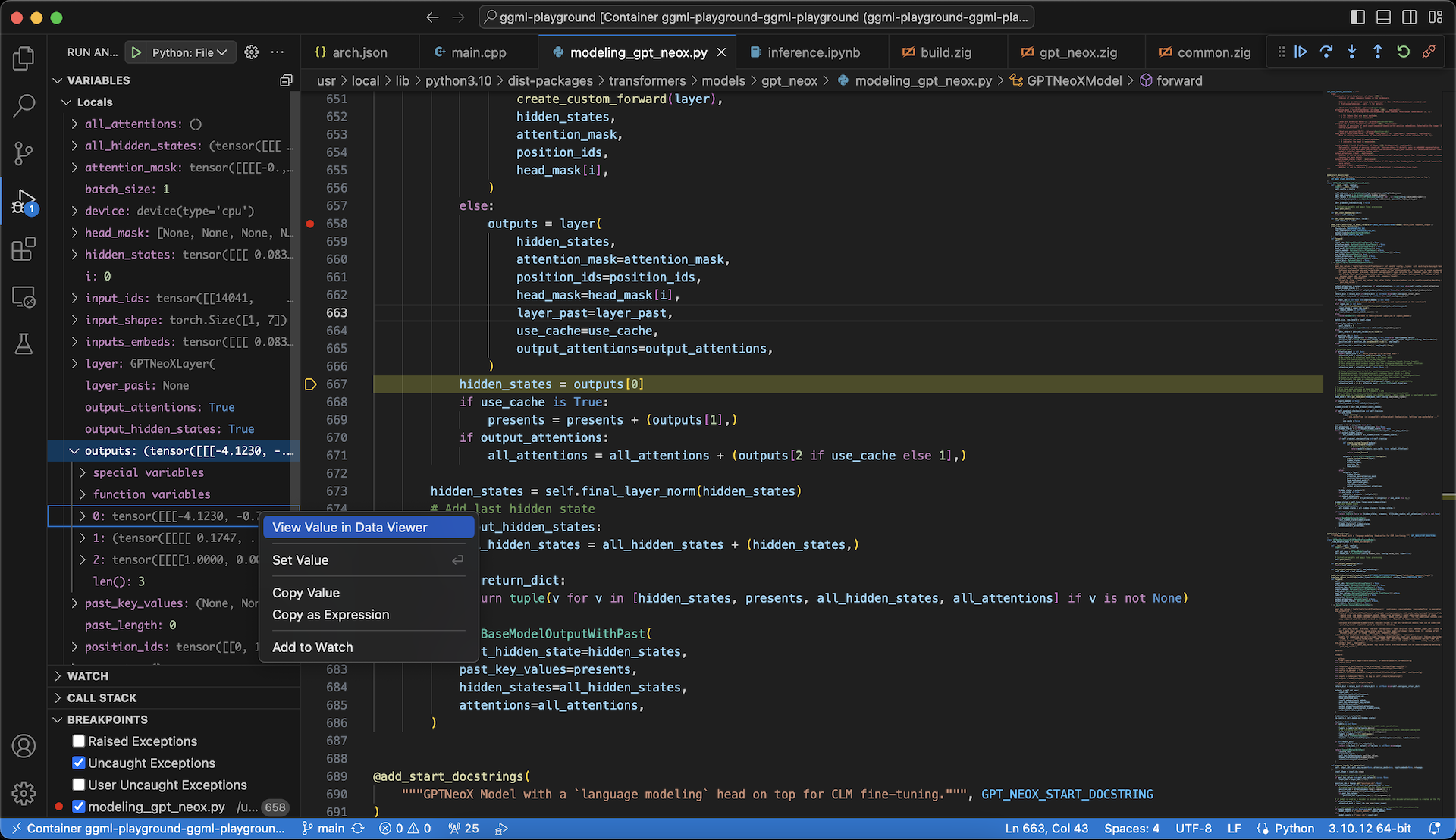
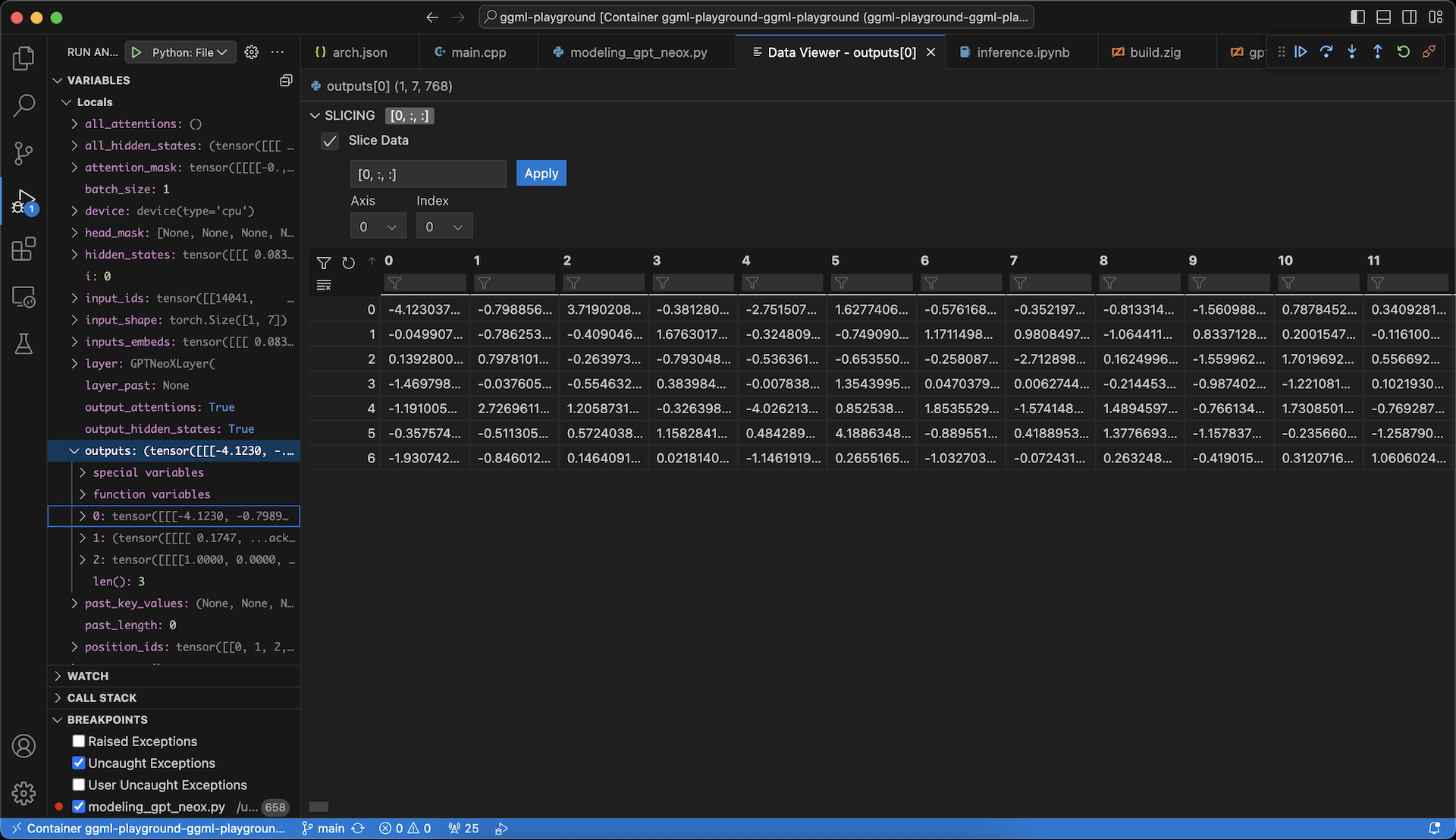
Some notes when using ggml
- It has a concept called a "context", which is responsible for managing memory for all tensors and computations. Every
ggmlfunction call takes place within this context, which ensures that there are no unexpected memory allocations. However, it also requires us to carefully choose the correct memory size for the context, which can be quite challenging, especially when working with large models. - The dimension order in
ggmlis the reverse of the dimension order used in PyTorch. In PyTorch the order isN x C x H x W, but inggmlit isW x H x C x N, with:N- the batch dimension,C- the channel dimension,H- number of rows, andW- number of columns.
Conclusion
While training ML models is an intriguing task, transitioning them into production, especially in environments with limited GPU resources like edge devices, comes with additional challenges, yet it can still be quite enjoyable. With the recent surge in ML, including the release of numerous models of various sizes, optimizing ML model inference for cost-effectiveness, improved performance, and better memory efficiency has become increasingly important.
Completing these tasks demands not only low-level system programming skills but also a profound understanding of mathematics and ML model architecture. It can be challenging and occasionally frustrating. However, in the end, when you witness your model running smoothly on an edge device with limited hardware and minimal memory requirements, you can be certain that your efforts have paid off. It results in a more prosperous business and, most importantly, happier customers.
Upcoming tasks for Part II
- Implement the entire text generation process.
- Cache keys and values of attention.
- Enhance performance and optimize memory usage with quantization.
- Utilize the tokenizer to extract token IDs from various input texts dynamically.