
この記事はマネーフォワードアドベントカレンダー 2021の15日目の記事です。
こんにちは。マネーフォワードサービス基盤本部インフラ部の@grezarです。先日、MySQLのMulti-Threaded Slave(以下、MTS)を本番で有効化した際にMTSの挙動について詳しく調査する機会があったのでこの記事で解説したいと思います。
そもそもMTSとは
MTS自体はMySQL5.6から登場したMySQLの機能で、従来のレプリケーションがシングルスレッドでしかトランザクションを実行できなかったところを、条件付きではあるものの、マルチスレッドで実行できるようにしたものです。これによって、高いスループットが求められるようなreplicaにおいてはシングルスレッドではレプリケーションの性能に限界があったところを一定の制約下のもと、マルチスレッドで実行することで高いスループットを実現することができるようになりました。MTSがどのようにマルチスレッドでのレプリケーションを可能にしているのかを理解する上で大切なのはprimary側でどのようにトランザクション間の依存を解決し、レプリケーション側では依存解決されたトランザクションをどのようなロジックに基づいて並列実行しているかを知ることです。これらのprimary側の依存解決のロジックと、replica側の並列実行のロジックの組み合わせによってMTSの動作は異なってきます。
MySQL5.6時点ではreplica側での並列実行方式にDATABASEというものが登場し、スキーマが別々のトランザクションに対してのみしかMTSを適用できませんでした。
MySQL5.7ではreplica側の並列実行方式にLOGICAL_CLOCKが加わり、これによってprimary側でグループコミットされたトランザクションについては同一スキーマであってもreplica側でもマルチスレッドで実行できるようになりました。
また、MySQL 5.7.22 及びMySQL 8からはprimary側のトランザクションの依存解決のアルゴリズムに(binlog_transaction_dependency_trackingにて指定)にWRITESET及びその亜種のWRITESET_SESSIONという方式が加わり、これによってトランザクションが変更した行に重複がない限りはグループコミットをしていなくてもreplica側での並列実行が可能になり、より高い並列性を実現できるようになりました。
現在では特殊な事情がない限りもっとも高い並列性を実現できるWRITESET(またはWRITESET_SESSION)とLOGICAL_CLOCKの組み合わせを使うのがよいと個人的には考えており、この記事では特にWRITESETによってprimary側でトランザクション間の依存解決がどのように行われるのかを詳しく解説していきます。
MTSにおける依存解決
当然の話しですが、トランザクションをreplicaで並列に実行しようと思ったらそのトランザクションは依存しているトランザクションのCOMMIT後に実行される必要があります。そうでなければトランザクションの実行順序が前後することによってprimaryとのデータの不整合が起きたり、そもそもトランザクションの実行自体に失敗するでしょう。これはシングルスレッドで直列にレプリケーションをしているような状態では問題になりません。単にマスターでCOMMITされた順番で実行していくことになるので通常は同じ条件で素直に実行していけば整合性が保たれます。
ただし、マルチスレッドでレプリケーションを実行する場合はこの限りではありません。MTSではマルチスレッドでレプリケーションを実行しますが、トランザクション間の依存解決をしない場合マスターと同じ順番で直列にトランザクションを実行していくことしかできません。なぜなら依存解決されていないトランザクションを同時に実行した場合には不整合が生じる可能性があるからです。そこで、マルチスレッドを活かしてレプリケーションの性能を出すためにはトランザクション間の依存の解決をどのように行うのかが重要になってきます。
マルチスレッドのレプリケーションで性能を出すためには実行可能な状態になったトランザクションをできるだけ早い段階から実行していく、すなわちあるトランザクションが依存しているトランザクションをできるだけ古いもの(sequence_numberが若いもの)に解決しておいて、そのトランザクションがCOMMITされた直後から実行していくということが大切になります。この依存の解決があまり賢くないとトランザクション実行までに待たなければならない時間が増えてしまいマルチスレッドを活かしきれなくなってしまいます。依存解決の最終的な目的は、あるトランザクションよりも前にCOMMITされていなければならないトランザクションのうち、可能な限り前に実行されたトランザクションを特定することです。
MTSではトランザクション間の依存の解決をprimary側で行い、その情報をbinlogに含めます。replica側ではbinlogに含まれた情報をもとに並列実行可能なトランザクションを判断し、並列で実行します。MTSを有効にしたときにreplica側でトランザクション間の並列実行可否の判定に利用するのが last_committed と sequence_number です。sequence_number は単純にトランザクションごとに連番となるように振られる番号です。binlogのローテート時にも引き継がれます。last_committed はそのトランザクションを実行するよりも前にCOMMITされている必要があるトランザクションを示すものです。この条件を満たすようにreplica側ではトランザクションを並列に実行していきます。
(以下はmysqlbinlogコマンドの実行結果から抜粋したもの。binlogの各行にlast_commitedとsequence_numberが含まれている)
#210617 18:26:30 server id xxxxxx end_log_pos 522359145 CRC32 0x5df71671 GTID last_committed=229643 sequence_number=229644 rbr_only=yes #210617 18:26:31 server id xxxxxx end_log_pos 522363726 CRC32 0x5fcd787d GTID last_committed=229644 sequence_number=229645 rbr_only=no #210617 18:26:31 server id xxxxxx end_log_pos 522363981 CRC32 0xf854f9f1 GTID last_committed=229645 sequence_number=229646 rbr_only=yes #210617 18:26:32 server id xxxxxx end_log_pos 522364434 CRC32 0x5d52b735 GTID last_committed=229645 sequence_number=229647 rbr_only=yes #210617 18:26:32 server id xxxxxx end_log_pos 522366622 CRC32 0xb9558655 GTID last_committed=229645 sequence_number=229648 rbr_only=yes #210617 18:26:37 server id xxxxxx end_log_pos 522368805 CRC32 0xbbc0aa51 GTID last_committed=229645 sequence_number=229649 rbr_only=yes #210617 18:26:37 server id xxxxxx end_log_pos 522370014 CRC32 0x60d4521b GTID last_committed=229645 sequence_number=229650 rbr_only=yes
先程も述べましたが、MTSはprimary側でのトランザクション間の依存解決のロジックとreplica側での並列実行方式の組み合わせによってどのように動作するかが変わります。 それぞれ設定上のパラメータとしてはprimaryがbinlog_transaction_dependency_tracking 、replicaはreplica_parallel_typeで指定します。
binlog_transaction_dependency_trackingには COMMIT_ORDERとWRITESET(またはWRITESET_SESSION)、replica_parallel_typeには DATABASE と LOGICAL_CLOCK* の2つが指定可能です。ではそれぞれのパラメータがどのようにMTSの動作に影響を与えるかをより詳しく見ていきます。
まずはprimary側の設定です。
binlog_transaction_dependency_tracking
このパラメータではprimary側でどのようなロジックに基づいてトランザクション間の依存を解決するかを指定しています。 値にはCOMMIT_ORDERとWRITESET、WRITESET_SESSIONが指定可能です。
COMMIT_ORDER
primary側でのトランザクションの依存解決にCOMMIT_ORDERを用いる場合、トランザクションのgroup commitを有効化しないと意味がありません。もしgroup commitを有効化しなかった場合、last_committedの値は直前にCOMMITされたトランザクションの値になり、replica側では単にトランザクションが直列に実行されていくだけです。 (group commitは適切に設定すれば個別のトランザクションのレイテンシは増しますが全体のスループットは向上します)
WRITESET/WRITESET_SESSION
WRITESET及びWRITESET_SESSIONはトランザクションが変更を加えた行が重複しない限りはトランザクションを並列で実行可能にする依存の解決方法です。WRITESET_SESSIONは同一セッションのトランザクションは並列実行できないように依存を解決するという違いがあります。WRITESETはunique key/primary keyを含まないテーブルや、foregin keyを含むテーブルに対しては適用できません。その場合そのトランザクションの依存解決はCOMMIT_ORDERのときと同等になります。ここで、WRITESETによってどのようにトランザクション間の依存の解決が行われるかを実際のMySQLのコードから追ってみます。
トランザクションの依存の解決を行っている関数がこちらです。
void Transaction_dependency_tracker::get_dependency(THD *thd,
int64 &sequence_number,
int64 &commit_parent) {
関数内ではswitch-case文でdependency_trackingのモードを判定しており、binlog_transaction_dependency_trackingがWRITESETに設定されている場合でも先にCOMMIT_ORDERにてトランザクションの依存の解決を行っていることがわかります。その後、WRITESETによる依存の解決が行われます。これによって最低でもCOMMIT_ORDER方式による依存解決がされることになります。
switch (m_opt_tracking_mode) {
case DEPENDENCY_TRACKING_COMMIT_ORDER:
m_commit_order.get_dependency(thd, sequence_number, commit_parent);
break;
case DEPENDENCY_TRACKING_WRITESET:
m_commit_order.get_dependency(thd, sequence_number, commit_parent);
m_writeset.get_dependency(thd, sequence_number, commit_parent);
break;
case DEPENDENCY_TRACKING_WRITESET_SESSION:
m_commit_order.get_dependency(thd, sequence_number, commit_parent);
m_writeset.get_dependency(thd, sequence_number, commit_parent);
m_writeset_session.get_dependency(thd, sequence_number, commit_parent);
break;
default:
assert(0); // blow up on debug
/*
Fallback to commit order on production builds.
*/
m_commit_order.get_dependency(thd, sequence_number, commit_parent);
}
}
COMMIT_ORDERによる依存の解決が行われた時点ですでにcommit_parent(今のトランザクションが依存しているトランザクションのsequence number)は決定しており、WRITESETによる依存の解決でcommit parentをより小さな値、すなわちより以前にcommitされたトランザクションに解決しようとします。
そしてWRITESETでの依存の解決を行っている関数がこちらです https://github.com/mysql/mysql-server/blob/3290a66c89eb1625a7058e0ef732432b6952b435/sql/rpl_trx_tracking.cc#L208-L293
void Writeset_trx_dependency_tracker::get_dependency(THD *thd,
int64 &sequence_number,
int64 &commit_parent) {
関数の中身の詳しい処理を見ていきます。
ここでwritesetというものが登場します。これは、現在のトランザクションによって更新された行を一意に特定できるような情報、schema名、table名、primary keyなどを連結した文字列をhash化したものをvectorに入れたデータ構造として表現されています。writesetは現在のトランザクションによって更新された行の集合と考えれば良さそうです。
Rpl_transaction_write_set_ctx *write_set_ctx =
thd->get_transaction()->get_transaction_write_set_ctx();
std::vector<uint64> *writeset = write_set_ctx->get_write_set();
次に現在のトランザクションがWRITESETを使うための条件を満たしているかを判定します。例えばトランザクションがDDLであったりforeign keyを使っているテーブルを更新していたりする場合にはWRITESETによる依存解決を行うことができず、後述するhistory tableがリセットされることになります。
bool can_use_writesets =
// empty writeset implies DDL or similar, except if there are missing keys
(writeset->size() != 0 || write_set_ctx->get_has_missing_keys() ||
/*
The empty transactions do not need to clear the writeset history, since
they can be executed in parallel.
*/
is_empty_transaction_in_binlog_cache(thd)) &&
// hashing algorithm for the session must be the same as used by other
// rows in history
(global_system_variables.transaction_write_set_extraction ==
thd->variables.transaction_write_set_extraction) &&
// must not use foreign keys
!write_set_ctx->get_has_related_foreign_keys() &&
// it did not broke past the capacity already
!write_set_ctx->was_write_set_limit_reached();
WRITESETを使うための条件を満たしていた場合、依存の解決に進みます。依存の解決ではまず、現在のトランザクションのwritesetを現在保持しているhistoryに追加した場合にhistoryがあふれるかどうかを確認します。なお、ここでのhistoryのサイズは binlog_transaction_dependency_history_size パラメータによって設定できます(デフォルト値は25000)。もしhisotryのsizeを超過する場合は今回のトランザクションが変更した行をhisotryにすべて記録することができないので、この関数の最後でhistoryをpurgeします。次回以降の依存の解決はhistoryが空なので必然的にcommit orderによって解決されたトランザクションがparent commitとなります。
/*
Check if adding this transaction exceeds the capacity of the writeset
history. If that happens, m_writeset_history will be cleared only after
using its information for current transaction.
*/
exceeds_capacity =
m_writeset_history.size() + writeset->size() > m_opt_max_history_size;
現在のwritesetの各要素に対してhistoryに重複する変更がないかを確認していきます。 もしkeyが重複しているhistoryが見つかった場合は、その行を変更したトランザクションが現在のトランザクションのcommit parentとなります。 また、現在のトランザクションの変更と重複しているhisotryがない場合は次回以降利用するためにhistoryにその変更を記録していきます。
/*
Compute the greatest sequence_number among all conflicts and add the
transaction’s row hashes to the history.
*/
int64 last_parent = m_writeset_history_start;
for (std::vector<uint64>::iterator it = writeset->begin();
it != writeset->end(); ++it) {
Writeset_history::iterator hst = m_writeset_history.find(*it);
if (hst != m_writeset_history.end()) {
if (hst->second > last_parent && hst->second < sequence_number)
last_parent = hst->second;
hst->second = sequence_number;
} else {
if (!exceeds_capacity)
m_writeset_history.insert(
std::pair<uint64, int64>(*it, sequence_number));
}
}
ここまでのコードの中身を踏まえて簡単なアニメーションでWRITESETの依存解決の仕組みを解説します。まず、Writeset Historyがまっさらな状態から始めます。この状態では現在のトランザクションのwritesetはすべて現在のトランザクションのsequence_numberとともにHistoryに記録されることになります。

この状態に対して別のトランザクションが実行された場合が以下のとおりです。現在のトランザクションのWritesetとWriteset HistoryのKeyに重複がない場合、すべてのWritesetがWriteset Historyに追記されます。
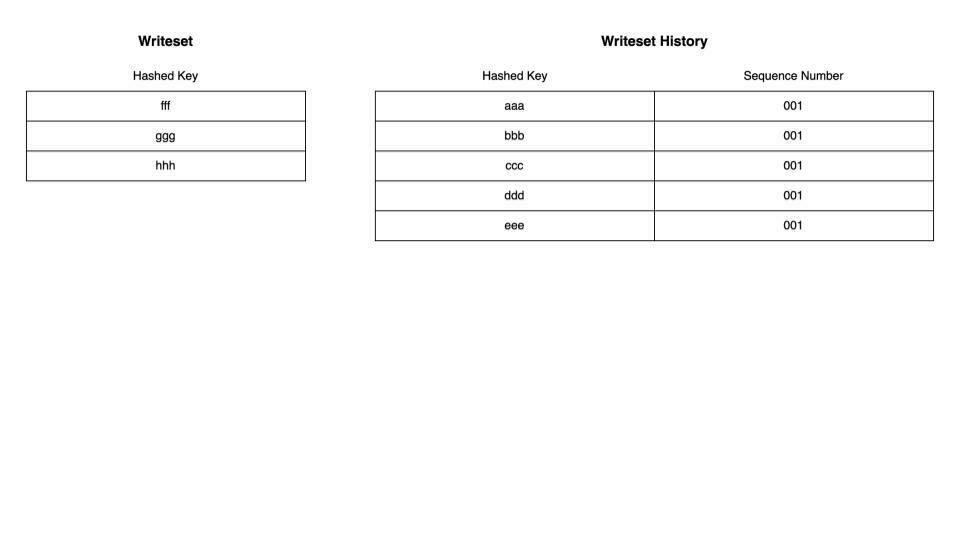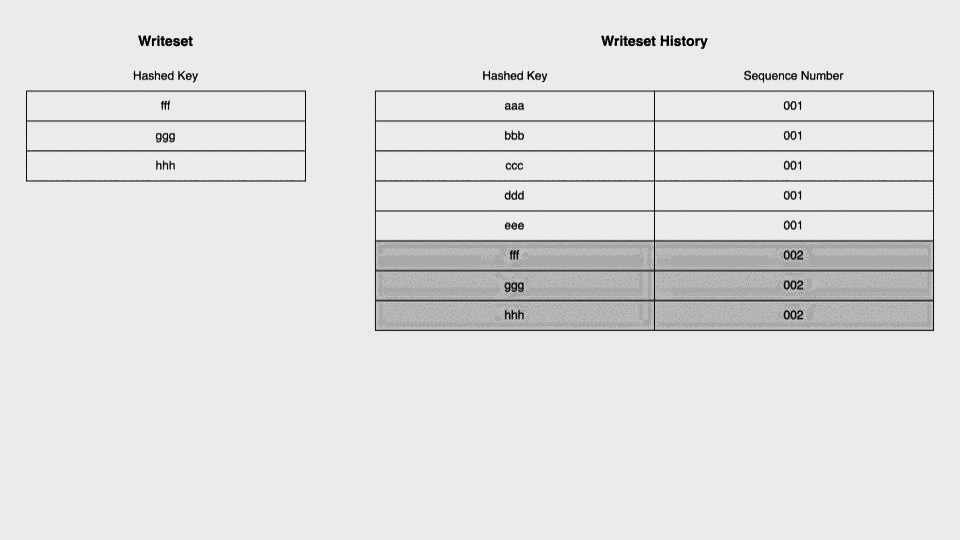
今度は現在のトランザクションのWritesetとWriteset Historyに重複がある場合です。重複している行についてはHistoryの該当する行のSequence Numberを現在のトランザクションのSequence Numberで置き換えます。また、現在のトランザクションのcommit parentはもともとHistoryに記録されていたSequence Number、この場合001になります。 これが意味するのは現在のトランザクションはreplicaにおいて、Sequence Number 001のトランザクションがCOMMITされたあとに実行する必要があるということです。 また、Writesetの中でWriteset Historyと重複していない行の変更についてはそのままHistoryに追記されます。
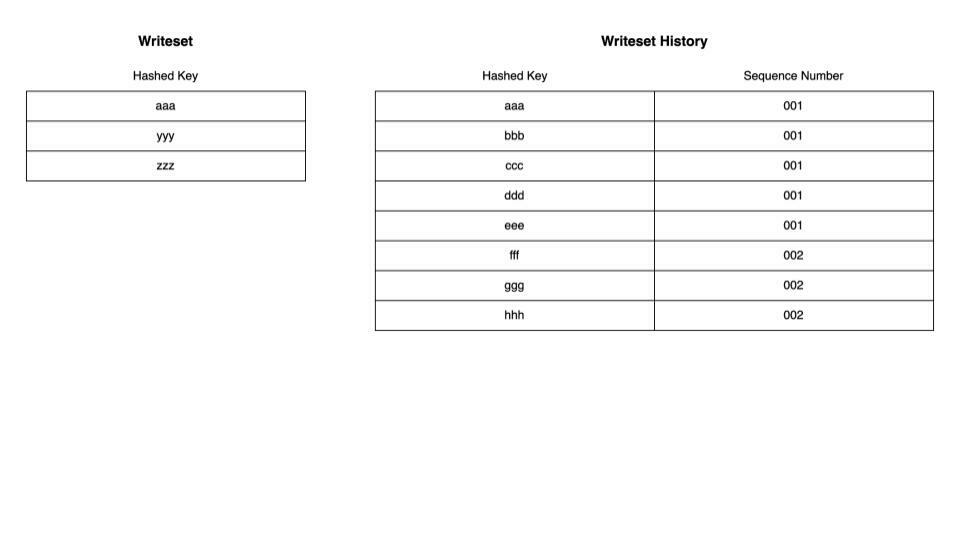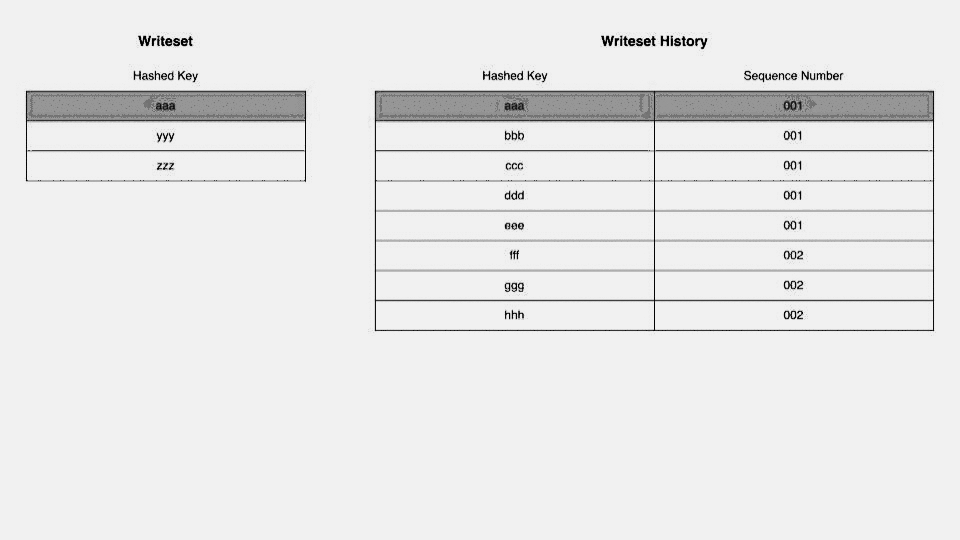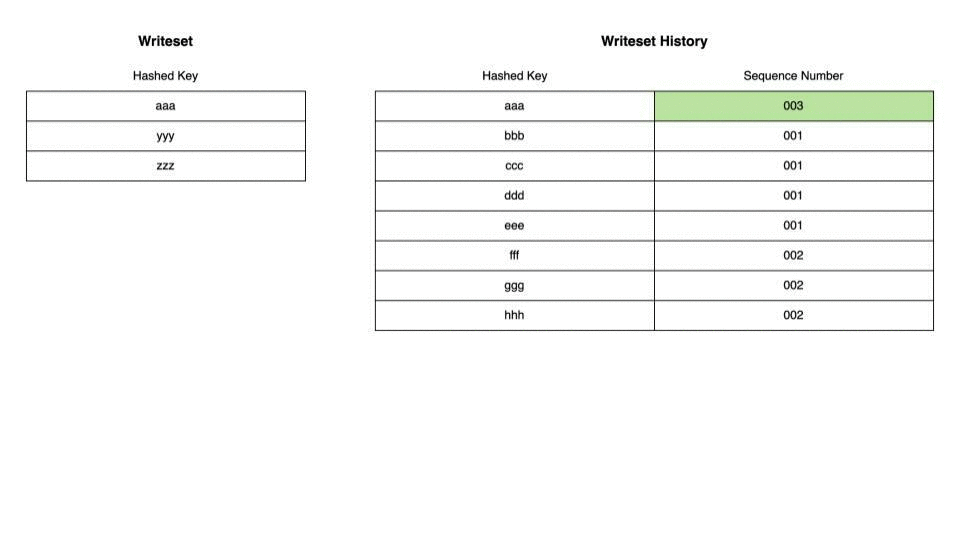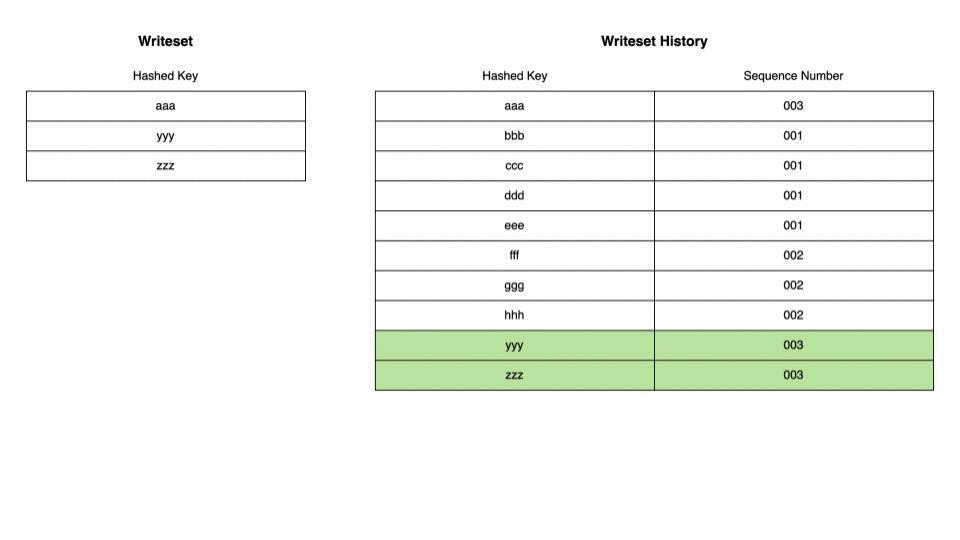
ここまでで、WRITESET方式での依存の解決において、現在のトランザクションが依存している最も古いトランザクションが決定しました。 WRITESETとCOMMIT_ORDERそれぞれの方式で依存しているトランザクションを解決した結果を比較し、より古い(=sequence numberが小さい)トランザクションをcommit parentにします。依存しているトランザクションが古ければ古いほどreplicaではトランザクションを早くから実行できるので並列性が増すことになります。
if (!write_set_ctx->get_has_missing_keys()) {
/*
The WRITESET commit_parent then becomes the minimum of largest parent
found using the hashes of the row touched by the transaction and the
commit parent calculated with COMMIT_ORDER.
*/
commit_parent = std::min(last_parent, commit_parent);
}
最後に必要に応じてhistoryのリセットを行います。 historyのサイズを超過した場合、またはwritesetを使えないトランザクションについては次回以降のトランザクションが過去の変更とconflictしているかどうかについて判定することができないのでhisotryをリセットする必要があります。
if (exceeds_capacity || !can_use_writesets) {
m_writeset_history_start = sequence_number;
m_writeset_history.clear();
}
以上がWRITESETによるトランザクションの依存の解決です。
次に、replica側での並列実行方式に関する設定です。
replica_parallel_type
DATABASE
もっとも原始的なMTSの方式です。単にbinlogに含まれているトランザクションの更新しているスキーマが違えばreplicaでも並列実行可能と判断してマルチスレッドで実行するようにする方式で、MTSの適用範囲は限定的です。
LOGICAL_CLOCK
この方式を使うにはprimary側でのトランザクションの依存解決がされていることが必須です。primary側でトランザクションの依存解決を行った場合には、binlogにlast_committedという項目が追加されます。last_committedはそのトランザクションがCOMMITされるまでにCOMMITされているべきトランザクション、すなわちあるトランザクションが依存しているトランザクションを指しています。LOGICAL_CLOCKはlast_committed が同じトランザクションについては並列で実行できるということを意味しています。適切に設定できていればDATABASEよりも明らかに並列性はますのでこちらの方式を選ばない理由は薄いでしょう。
MTSでのprimaryとreplicaのデータの一貫性についての補足
シングルスレッドでのレプリケーションではprimaryでCOMMITされた順番でreplicaでもトランザクションがCOMMITされていくだけなのでreplicaのどの断面をみてもprimaryに存在した状態になっていると言えるでしょう。しかし、MTSにおいてはデフォルトの状態ではreplica側でトランザクションがCOMMITされる順番というのは必ずしもprimaryとは一致しません。もちろん最終的なデータの一貫性は保たれますが(結果整合性)、例えばある時点でreplica側で引いたデータがprimaryにはない状態となってしまうことも考えら、それが問題になることもあるでしょう。そのような事態を回避するためにはCOMMITの順序はprimaryと揃えておくことが必要になり、そのためのパラメータがreplica_preserve_commit_order です。このパラメータは有効にしておくのが無難でしょう。
まとめ
基本的には
# primary binlog_transaction_dependency_tracking=WRITESET transaction_write_set_extraction=XXHASH64 # replica replica_parallel_type=LOGICAL_CLOCK replica_preserve_commit_order=1
が良さそうです。
binlog_transaction_dependency_history_sizeはprimaryの書き込み負荷によってチューニング。より古いトランザクションまで依存の解決時に遡れるようになればreplica側での並列性が増します。ただし、hisotryのサイズが大きくなればなるほどトランザクションごとの依存の解決に時間がかかるようになるのでレイテンシは増えます。また、historyをとても大きく確保したとしても途中でWRITESETを使えないようなケース、すなわちDDLやforeign keyを含むテーブルの変更などが行われた場合にはhistoryがリセットされてしまうので、historyのサイズが大きすぎる場合はすべてをを使い切るケースはほとんどなさそうです。replica側では並列数が増すので通常はCPUの利用率が増えます。当然これ自体は望ましいことですが、参照の負荷とのバランスも考えておく必要ありそうです。
マネーフォワードでは、エンジニアを募集しています。 ご応募お待ちしています。
【サイトのご案内】 ■マネーフォワード採用サイト ■Wantedly ■京都開発拠点
【プロダクトのご紹介】 ■お金の見える化サービス 『マネーフォワード ME』 iPhone,iPad Android
■ビジネス向けバックオフィス向け業務効率化ソリューション 『マネーフォワード クラウド』
■だれでも貯まって増える お金の体質改善サービス 『マネーフォワード おかねせんせい』