
こんにちは。 2021年10月からマネーフォワード クラウド勤怠の開発チームでSREとして働いています、VTRyo です。
入社2週間経過ブログを書いて以来の登場です。 https://moneyforward.com/engineers_blog/2021/10/28/mf-on-boarding/
現在の僕は、チーム一人目のSREとして活動しています。せっかくなので、SRE立ち上げ記を綴っていきます。
第1話は 「サービスの状態を可視化して、まずはチームメンバーに安心を与えていこうな」 という話をします。
話さないこと
- SREそのものについて
- 具体的な作業ログ
経緯
10月某日。入社オリエンや開発オリエンが終わって徐々にSRE活動を始めることになりました。
必要なチャンネルに一通り招待され、どんなやり取りが発生するかを把握していきます。 そこで、真っ先に気になったのはモニタリングに関することでした。
errorsチャンネルに、Rollbarでトラッキングされたエラーが四六時中ずっと流れています。

通知だけされていて「あ、これは通知はされていますがユーザ影響のないものです」といった、いわゆるオオカミ少年と化していました。
トラッキングすることに価値はありますが、そのすべてが優先度高であるわけではありません。 開発者が単に把握しておきたいものもトラッキングします。ユーザにとって致命的なこともトラッキングします。
つまり、通知は適切にしなければ開発者は疲弊し、不安を抱きます。
- 通知が出た
- 何のエラーだ?
- 致命的なものか?
- 俺のデプロイのせいか?
- 平気なやつか?
- これ前にも見たやつじゃねえか!!
と毎日毎日やられると、恐らくミュートにするか、errorsチャンネルは常に未読があると思って何も感じなくなるだけです。
こうして脳が破壊されていくと、人間は本当に致命的なエラーの場合にも鈍感なまま対応できなくなってしまいます。 何より毎日疲弊している状態なので、そのチャンネルすら見たくありません。
人間、見えないものには不安を抱くものです。SREとしてやるべき仕事は無数にありますが、まずは 「プロダクトは今健全なのか?どういう状態なのか」 を可視化することにしました。
誤報が通知され続けることが常態化しているように見えたので、まず開発者のペインを取り除くこと。チームがより健全な活動ができる状態にすることから始めてみました。
つくったもの
流れとしては、始めはオオカミ少年の呪いを解こうと計測したことから始まります。
- トラッキングされているものの優先度をつけるためにエラー数を計測しよう
- 優先度が低いもの、高いもので整理しよう
- せっかくだしダッシュボードにして誰でも見られるようにしよう
そして最終的につくったものはこちらです。 システムの概要と重要なリソースを集約してあります。
障害時や定点観測でも使うことを想定して、暫定的に整理した形です。
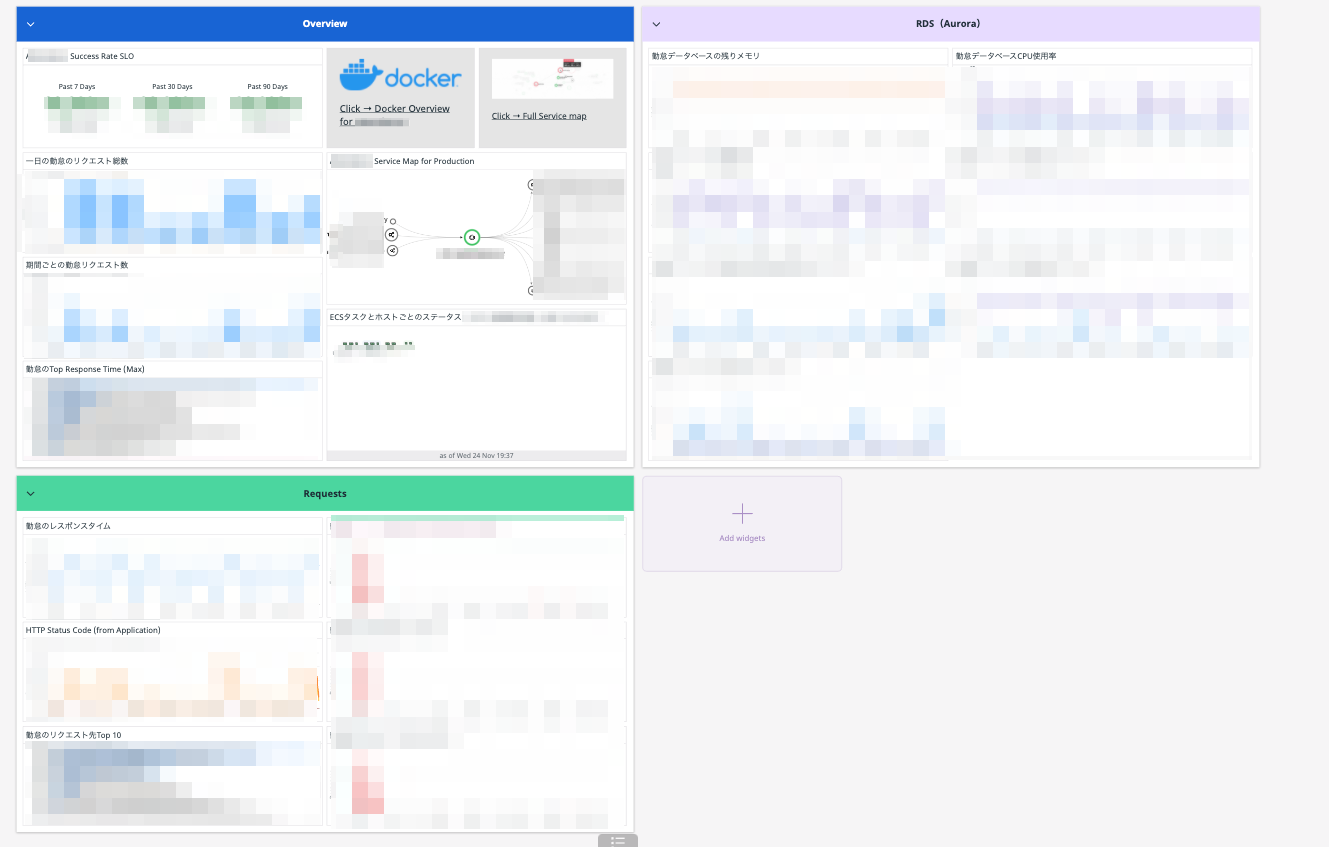
Overviewでは、システムにとって重要な要素をピックアップして並べておきました。
ここを見れば、まずはシステムの健全性がわかるでしょう。
- システムのSLO
- リクエスト数
- サービスマップ
- レスポンスタイムの遅いエンドポイント
- コンテナのステータス
- Docker Overviewで詳細も見れるようにリンクを置いてある
Requestsでは、リクエストやレスポンスに関する要素を並べています。
期間ごとの数値が見て取れます。体感より5xxは少ないな??ということを把握できます。
- レスポンスタイム
- HTTP Status Code
- リクエスト先Top10
- エラー数
- etc...
RDSではその名の通り、RDSに関するリソース状態を並べています。
- CPU
- Memory
- Connection
- etc...
ここからは、このダッシュボードを作る過程で取り組んだことも書いていきます。
計測する
取り組み時点で、以下のことがわかっていました。
- トラッキングされたすべてのエラーに対応するリソースはない
- 対応しなくてもユーザに影響がなさそう(静観してみたが「機能が使えない」といったの問い合わせはなかった)
すべてのトラッキングがチャンネルに通知されると、漠然と「なんか毎日通知がされてるな……」とモヤモヤする状態になってしまいます。 それではしんどいので、まずは一日のうちどれくらいユーザ影響のあるエラーが出ているのかを可視化してみることにしました。
推測するな、計測せよ by Rob Pike
まずはオーソドックスな指標である、5xxと全体のリクエストとの割合をみることにします。 (5xx→リクエストを処理できなかった→ユーザは機能を使えなかった、ということであり、重要な指標の一つと言えるでしょう)
DatadogにはSLOを設定できる機能がついているので、それを利用して仮のSLOも一緒に設定しておきます。 SLOはリクエスト成功率が99.9%を保っているのであれば、まずは良いということにします(SLOの定義は、SREチームの成熟とともに再設計・再定義していき、少しずつ精度を上げていくのが良いと思います)。
リクエスト成功率 = Goodリクエスト(2xx, 3xx, 4xx) / 全体のリクエスト(2xx, 3xx, 4xx, 5xx)
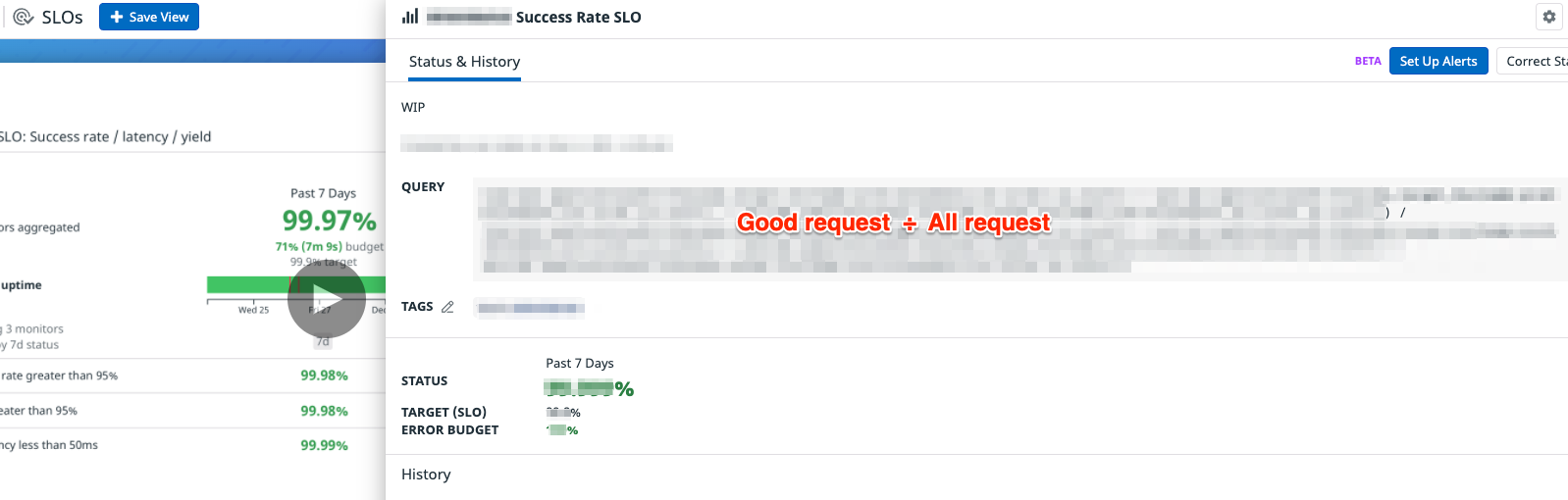
なおこの結果、SLOターゲットは十分にクリアできていることがわかりました。 例えば SLOターゲットが99.99%で1日100万リクエストの場合、エラー数が1日100回以下になっていればプロダクトとしては許容できると言えます。 ※前提として、SLOターゲット100%を目指すことはありません。
つまりSREはこのデータを元に、エラートラッキングや通知のしきい値を変更することができます。
オオカミとなった少年の呪いを解く

無数の通知を出していたerrorsチャンネルには、Datadogではエラーレートによる通知やサービスダウンのような致命的な通知のみに変更しました。
さらにトラッキングしていたエラーは、しきい値を緩く(Rollbarの通知設定がEvery OccurrenceになっていたのをHigh Occurrence Rateに変更)した上で、noticeチャンネルへ移設しました。
これにより、未読チャンネルに対する開発者の意識が変わってきます。
- noticeチャンネル: 何度も出る通知は把握できる(優先度低での対応とわかる)
- errorsチャンネル: エラー率が高い、サービスに影響があるときにだけ通知が来る(優先度高く対応すべきものとわかる)
メンバーからの感想:
(日常的に表示されていた通知を見て)「いつ直せば良いのか?直せないチームはそもそも良くないのではないか?などの不安要素が減って、メイン開発に以前より集中できるようになった」
また、僕自身も通知が整理されたことで「未読がある。何かあったな」とすぐに反応し、起票と一時調査に移れます。
「毎日のように誤報通知されて、知らぬ間に疲弊する」という状況を脱するだけなら、これでも十分に効果があるでしょう。
今後は通知に障害対応時の手順や優先度の考え方を埋め込むなどして、ネクストアクションを促すように改善していく方向になります。
プロダクトの状況が一箇所で見える
先述したように、ダッシュボードにはシステムに関する情報を載せています。 それまでは、そもそもどこを見ればリソースを把握できるのかすぐにわかりませんでした(情報共有ツールを検索しまくって手順を探すことになる)。
CloudWatchなのか、Datadogなのか、監視ツールが分散していてもあまりいいことはありません。 Datadogを採用しているならば、そこに多くの情報を集約することで関連情報へのジャンプが圧倒的に楽です。

※情報を集めておくほどView related xxxで探せる
開発者自身がシステムがどうなっているのかを見に来るハードルが下がれば、チームにとっては大成功です。
参考
この記事内容を実施するのに参考となる書籍とブログです。
おわりに
おぼろげながらにしか見えていなかったサービスの現実が、Datadogのフル活用によってはっきりと見えるようになってくるはずです。
今回、まずは目の前にいる開発者のペインを取り除きたい、と思って変更活動をしました。開発者の生産性を上げつつ、可用性も担保できるようにさらに活動していきたいですね。 その第一歩ができたということで、第一回目のSRE立ち上げ記は締めたいと思います。
弊チームでは、SRE活動を1から始めています。バックエンドスキル、フロントエンドスキル、インフラスキルなど(もちろん全部でも良いですぞ)を活かしたSRE活動に興味のある方、ぜひお話だけでもお待ちしてます。
ではまた次回。
マネーフォワードでは、エンジニアを募集しています。 ご応募お待ちしています。
【サイトのご案内】 ■マネーフォワード採用サイト ■Wantedly ■京都開発拠点
【プロダクトのご紹介】 ■お金の見える化サービス 『マネーフォワード ME』 iPhone,iPad Android
■ビジネス向けバックオフィス向け業務効率化ソリューション 『マネーフォワード クラウド』
■だれでも貯まって増える お金の体質改善サービス 『マネーフォワード おかねせんせい』