
こんにちは。 マネーフォワードでエンジニアとして働いているgotoken(@kennygt51)です。 今回は、当社の提供するサービスの一部が稼働しているEKSクラスタにCluster Autoscalerを導入した話をします。
Cluster Autoscalerとはなにか
Cluster AutoscalerとはKubernetesクラスタのNodeのオートスケーリングを実現するツールです。需要に応じてKubernetesクラスタのNodeを自動的に追加・削除します。
Cluster Autoscalerがトリガされるタイミングは2つあります。Nodeが増えるタイミング(スケールアウト)と、Nodeが減るタイミング(スケールイン)です。
スケールアウトはリソースが足りない状態になるとトリガされます。ここでいう「リソースが足りない」とは、Podが起動できない状態になった(Pending状態のPodが存在する)という意味です。逆にスケールインは、リソース過多の状態になるとトリガされます。「リソース過多」とはPodのResource RequestsをみたときにそのNodeで動いているPodが他のNodeで動かせるという意味です。
つまり、クラスタ全体やNodeのロードアベレージが上下した際にスケールするのではなく 「Pending状態のPodができたタイミングであったりNodeのリソースに対して稼働中のPod数が少なくなったタイミングでスケールする」 という挙動になります。
なぜCluster Autoscalerを導入しようとしたのか
実は当社のEKSクラスタは当初、Cluster Autoscalerを導入していませんでした。
理由としては次の2点です。
- EKSクラスタの運用開始当初に稼働していたサービスでは、オートスケールがそこまで必要とされていなかったこと
- 運用コストを下げるため、可能な限り運用・管理していくコンポーネントの数を減らす(あるいはマネージドサービスを使っていく)方針でEKSクラスタの構築を進めていたこと
そんな中、オートスケール導入によるメリットが大きいサービス(時間帯や時期による負荷の増減が激しくトラフィック量も多い)がEKSクラスタ上で稼働する要件が発生したため、運用負荷があがったとしてもオートスケールを導入した方がメリットが大きいという判断になりました。サービスのオートスケールにはHorizontal Pod Autoscalerを導入することになりますが、いくらPodの数が増えてもNodeの数が増えなければスケールアウトは頭打ちになってしまいます。そのため、早急にCluster Autoscalerを導入する必要がありました。
本番稼働するEKSへのCluster Autoscaler導入にあたっての考慮事項
既にいくつかのサービスが本番稼働しているEKSクラスタにCluster Autoscalerを導入するにあたって、いくつか考慮すべき点がありました。
- スケールイン時のPodの退避
- EKSクラスタをTerraformで構築したため、実リソースとコードが乖離する
- Cluster Autoscalerを専用のNamespaceで動かす
- スケールイン/スケールアウトのSlack通知
各々の考慮事項について詳しく説明します。
スケールイン時のPodの退避
ClusterAutoscalerはNodeをスケールさせる際にAutoScalingグループのDesired Capacityの値を書き換えることでNode数を増減させます。スケールインがトリガされたタイミングでNodeは削除されますが、Nodeが削除される直前に、当該Node上で稼働しているPodを別のNodeに退避させる必要があります。 これを実現するためには、AutoScalingグループのLifeCycleHook機能を用いて、EC2インスタンスをTerminateさせる直前に当該NodeのPodをevictするワークロードを動かす必要があります。(amazon-k8s-node-drainerはLambdaを使って当該処理を動かすツールのようです) 当社のEKSクラスタでは、EC2インスタンスがTerminateされるタイミングで当該NodeのPodへのdrainを実行する独自ツールを導入することで、Nodeが削除される前にPodを別Nodeに退避させる運用をおこなっています。
EKSクラスタをTerraformで構築したため、リソースとコードが乖離する
当社のEKSクラスタはTerraformを使って構築されています。
Worker Node(EC2)を起動するAutoScalingグループのコードにおけるMax Size・Min Size・Desired Capacityを定義する箇所を抜粋しました。
Cluster Autoscaler導入以前は、全てのパラメータを同じ値にして一定のインスタンス数が起動し続ける設定にしていました。稼働するサービスが増えてリソースが足りなくなったら、クラスタ管理者がTerraformのコードを修正してNode数を増やすという運用をおこなっていました。
resource "aws_autoscaling_group" "eks_cluster" {
name = "${var.environment}-eks-worker-node"
max_size = local.eks_worker_node["max_size"][var.environment]
min_size = local.eks_worker_node["min_size"][var.environment]
desired_capacity = local.eks_worker_node["desired_capacity"][var.environment]
・・・
locals {
eks_worker_node = {
min_size = {
prod = 4
test = 2
}
max_size = {
prod = 4
test = 2
}
desired_capacity = {
prod = 4
test = 2
}
}
}
先程も述べたとおり、Cluster AutoscalerをEKSに適用する場合、AutoScalingグループのDesired CapacityをCluster Autoscalerが書き換えることで、Node数が増減します。
Cluster Autoscalerを導入すると動的にDesired Capacityの値が変わるので、このままでは実際のリソースとTerraformのコードが乖離していまいます。
ここでTerraformのAPI Docsを読んでみると、次のとおりdesired_capacityの指定はOptionalと記載されています。
desired_capacity - (Optional) The number of Amazon EC2 instances that should be running in the group.
そこでdesired_capacityにnullを設定することで、desired_capacityのパラメータをTerraformの管理化から外すことにしました。
またCluster Autoscaler導入直前に起動していたNode数をMin Sizeに指定し、Cluster Autoscalerによってスケールアウトして欲しい上限値をMax Sizeに指定しました。
具体的なコードは次のようになります。
locals {
eks_worker_node = {
min_size = {
prod = 4
test = 2
}
max_size = {
prod = 8
test = 4
}
# Cluster Autoscalerを導入したため、Desired CapacityはScaleOut/In時に動的に変わる
# そのためコード上はnullを設定しておく
desired_capacity = {
prod = null
test = null
}
}
}
Cluster Autoscalerを専用のNamespaceで動かす
Cluster Autoscalerのサンプルマニフェストを見るとkube-system Namespaceで動かすよう設定されています。
当社のEKSクラスタでは、インフラ系のコンポーネントを導入する際にはNamespaceを分けて導入していたので、今回もcluster-autoscalerというNamespaceで動かそうとしたところ、Cluster Autoscalerの起動に失敗しました。
公式ドキュメントを参照したところkube-system以外で起動する場合、Cluster Autoscalerの起動コマンドの引数でnamespaceを指定する必要がありました。

そこでマニフェストのnamespaceの指定に加えて起動コマンドの引数を変更することで、任意のNamespaceで起動することに成功しました。
スケールイン/スケールアウトのSlack通知
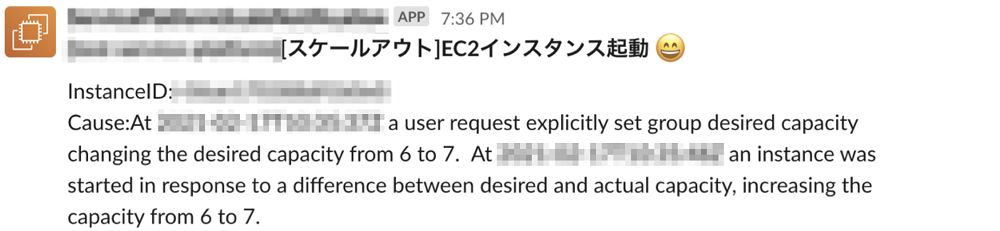
Cluster Autoscalerを運用するにあたって、こなれるまではスケールがトリガされたタイミングを知りたいというモチベーションがありました。 様々な実現方法がありますが、今回はSNSとLambdaを使って通知の仕組みを作りました。
次の流れでAutoScalingグループのEC2インスタンスの開始/終了イベントをSlackに通知します。

- AutoScalingグループの起動/終了通知をSNSに通知する
- 受け取ったメッセージをトリガにLambdaを起動
- SlackのIncoming WebhooksにメッセージをPOST
Cluster AutoscalerによりAutoScalingグループのDesired Capacityが書き換えられ、スケールイン/スケールアウトされたタイミングで、次のメッセージがSlackにPOSTされます。
Cluster Autoscalerを導入した結果
前述した考慮事項を考慮したうえで、Cluster Autoscalerを本番に導入することに成功しました。 今まではPodがリソース不足で起動しない時にクラスタ管理チームにエスカレーションが来てNodeを増減させる対応をおこなっていましたが、勝手にNode数を増やしてくれるのでその対応が必要なくなりました。 またHorizontal Pod Autoscalerを導入する準備も整ったので、EKSクラスタ上で稼働するサービスはオートスケールさせることが可能になりました。
最後に
マネーフォワードでは、よりよいインフラ、よりよいプラットフォームを作りたいという想いを持ったエンジニアを募集しています。 ご応募お待ちしています。
【サイトのご案内】 ■マネーフォワード採用サイト ■Wantedly ■京都開発拠点
【プロダクトのご紹介】 ■お金の見える化サービス 『マネーフォワード ME』 iPhone,iPad Android
■ビジネス向けバックオフィス向け業務効率化ソリューション 『マネーフォワード クラウド』
■だれでも貯まって増える お金の体質改善サービス 『マネーフォワード おかねせんせい』