
おはこんばんちは、CTO室AI推進部の@ken11です。 みなさん1021回目の夏はいかがお過ごしですか? 僕はあっという間に8月が過ぎ去ろうとしていることに戦々恐々としています。 どうせ今年もなにもできなかったな〜って言いながら若者のすべてを聴いて勝手にエモくなって最後の花火もなにも最初の花火すらないまま気づいたら9月になってる、そうそれがSummer。
みんな、人生の宝物を探しながら強く生きような。
実験管理
ところでみなさん実験は好きですか? オペレーションウルドとかそういうやつかもしれない、僕も秋葉原にラボを構えて昼飯にサンボで牛丼食べてドクペを飲むような人生になりたかった。
戯れ言もほどほどにして、今日は実験を管理する話をしたいと思います。 機械学習、MLの業務で発生する実験管理というものの話を。
そもそも実験管理ってなんだって話なんですが、学習時に発生する試行錯誤の軌跡をどのように管理していくかというものですね。 たとえば最初のタスクではlearning_rateを3e-5に設定して学習したけれど、2回目のタスクでは0.1に設定して学習したとか、3回目のタスクでは学習データに新しいものを利用したとか、それぞれどういう学習をしたときに、どういう結果(モデル)になったかというのがわかるように管理する、という話です。
これはすごく大事なことなのに意外と手間だったりする。
SageMaker ExperimentsとQuickSight
前回も言いましたが僕はAWS大好き芸人なのでこの実験管理もSageMakerでやっていきます。 SageMakerにはExperimentsという実験管理用のツールがあるんですが、コンソールメニューはなくSageMaker StudioしかUIがないので、恐らく知らない方も多いと思います。
しかしStudio上でしか見られないことはネックでもあり、というのも実験管理はその性質上、社内(場合によっては社外)のステークホルダーに対する説明でも利用する可能性があるので、なるべく気軽に見られる状態にしておきたいです。 なので今回はこのSageMaker Experimentsを可視化するのにQuickSightを使っていこうというわけです。
このお話は前回紹介したSageMakerとStepFunctionsの話の延長になっており、実は前回のリポジトリもサクッと更新しているのでどうぞこちらもご活用いただければと思います。
こういうStepFunctionsを使って

こういうグラフをつくっていきます
Experiments
SageMaker Experimentsは大きく3階層にわかれています。
- Experiment
- Trial
- TrialComponent
Experimentが最上位の概念で、そのなかに複数のTrialがあり、さらにTrialのなかには複数のTrialComponentがあります。 といっても全然想像がつかないので、いまの僕の使い方を紹介すると、
- Experiment: プロジェクト単位にわけてます
- Trial: 学習タスクごとにわけてます(学習実行時のタイムスタンプごとにつくってます)
- TrialComponent: 学習タスク内のフェーズごとにわけてます(前処理/学習/評価)
たとえば、Aというプロジェクトの、8月19日に実行した学習の場合、Experimentの名前はAでTrialの名前は0819でTrialComponentにはPreprocessとTrainとEvaluationがある、みたいな感じです。 この辺は特に決まりがあるわけじゃないので、管理しやすい形でいいと思います。
実はSageMaker ProcessorやTrainingを使うと、特に意識しなくてもこのExperimentは記録されていたりするんですが、後々振り返るには上述のようにきちんと名前を付けた方がよいです。
StepFunctionsでこの名前を指定するにはStepの作成時に引数 experiment_config を渡してあげることになります。
return ProcessingStep( "Preprocessing step", processor=preprocessor, job_name=self.execution_input["PreprocessingJobName"], inputs=inputs, outputs=outputs, experiment_config={ 'ExperimentName': 'hoge-project-name', 'TrialName': '202108190000', 'TrialComponentDisplayName': 'Preprocess-no-phase-dayo' }, container_entrypoint=[ "python3", "/opt/ml/processing/input/code/preprocess.py" ], )
こちらの抜粋ですがこんな感じですね。 TrainingのStepでも同様です。 これだけで放っておいてもなんかいい感じに必要な項目を記録してくれるので、Experimentsは便利です。
また、Training時のlossやaccuracyを記録しておきたい場合はEstimatorをつくるときに metric_definitions を設定する必要があります。
metric_definitions=[
{'Name': 'train:loss', 'Regex': '.*?loss: (.*?) -'},
{'Name': 'train:accuracy', 'Regex': '.*?accuracy: (0.\\d+).*?'},
],
ここで指定する内容はコンソールからトレーニングジョブをつくったときの

ここにあたるものですね。 ドキュメント的にはここら辺です。
また、 Tracker というクラスを使うと好きなものをExperimentの記録に含めることが可能なので、モデルの評価フェーズではこのようにaccuracyを記録することができます。
accuracy_score = model.evaluate(x_test, y_test, verbose=0)[1] with Tracker.load() as processing_tracker: processing_tracker.log_parameters({"evaluate:accuracy": accuracy_score})
このように、幅広い項目を記録して管理できるのがSageMaker Experimentsの魅力です。
Experimentsで記録した情報をS3にアップロードする
さて、前述の通り、Experimentsでは記録しても基本的にStudio上でしか確認ができないので、これをQuickSightで参照できるようにS3にアップロードしたいと思います。
StepFunctionsを使って、前処理→学習→評価まで終わったあとに、さらにもう1ステップ追加して、実験記録をS3にアップロードしていきます。

実はExperimentsで記録された情報は、前回も紹介したSageMakerのSDKにあるExperimentAnalyticsクラスを使うことで、pandasのデータフレームとして取り出すことが可能です。
def lambda_handler(event, context): experiment_name = event['experiment-name'] bucket_name = event['experiment_bucket_name'] key = event['experiment_key'] trial_component_analytics = ExperimentAnalytics( experiment_name=experiment_name, input_artifact_names=[] ) df = trial_component_analytics.dataframe() s3 = boto3.resource('s3') s3_obj = s3.Object(bucket_name, key) s3_obj.put(Body=df.to_csv(None).encode('utf_8_sig'))
(lambda_handlerのメソッドにそのまま全部書いちゃうという雑な感じですみません) こんな簡単にExperimentをCSVにしてS3にアップロードできてしまうのです。
このLambdaのStepを最後に追加しておくことで、学習が終わったら毎回Experimentが最新の状態でS3にアップロードされるようにしておきます。
QuickSightで可視化する
最後に、先ほどのExperimentのCSVがアップロードされる場所をQuickSightのデータセットにして可視化していきます。
{ "fileLocations": [ { "URIs": [ "s3://**********/*********.csv" ] }, { "URIPrefixes": [ ] } ], "globalUploadSettings": { "format": "CSV", "delimiter": ",", "textqualifier": "'", "containsHeader": "true" } }
このようなURIsにアップロードされたCSVのURIを指定した manifest.json を用意して、QuickSightのデータセットに登録していきます。
インポート完了後はお好みの形でダッシュボードをつくっていくだけです!

こんな感じで、テーブルにして学習ごとに使われたデータの場所・ハイパーパラメータを眺めて確認したり
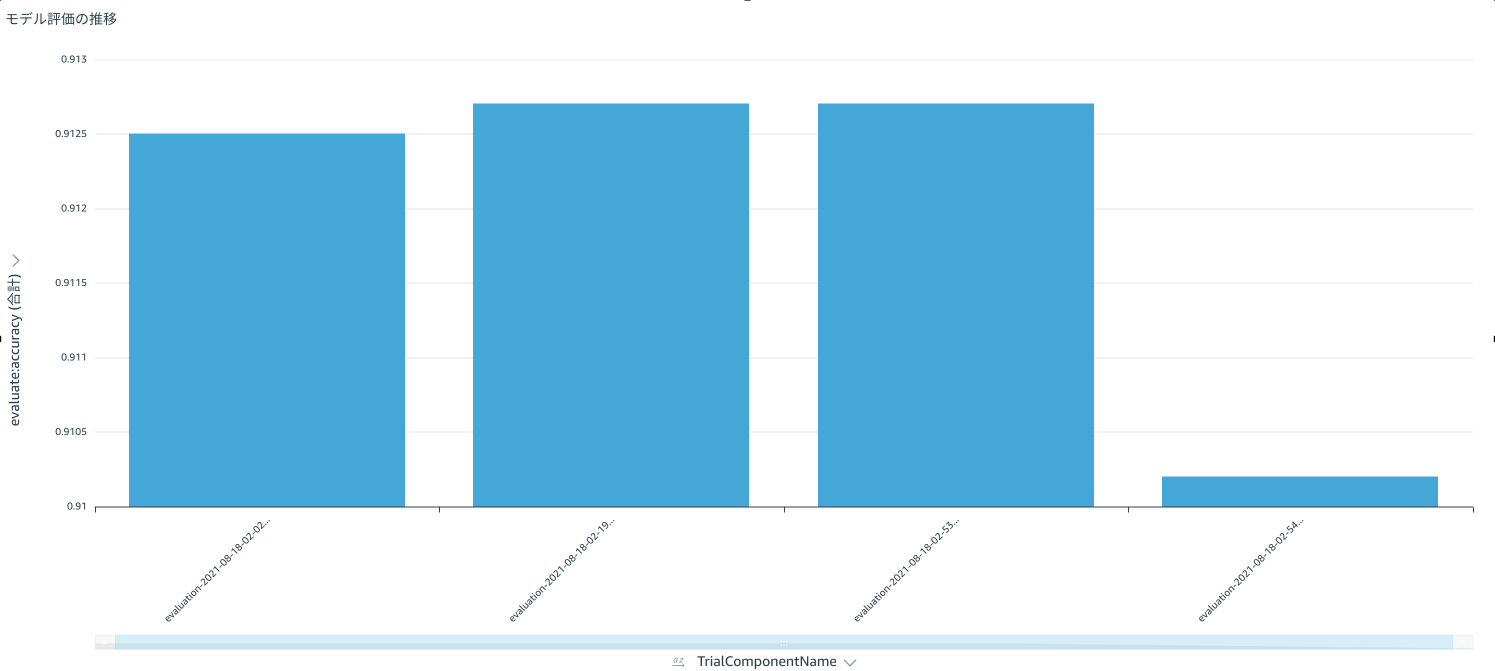
 学習を重ねるごとにモデル評価がどのように推移しているか確認したり
(4回目でだいぶ下がったな〜みたいな)
学習を重ねるごとにモデル評価がどのように推移しているか確認したり
(4回目でだいぶ下がったな〜みたいな)
ニーズにあわせて可視化していくことができます。 今回はQuickSightの紹介ではないので詳細は省きますが、QuickSightは権限管理も細やかにできるので、ダッシュボードツールとしてとても便利ですよ!
まとめ
というわけで、いまAI推進部で鋭意取り組んでいる実験管理を紹介させてもらいました。 日々、自動で学習を繰り返していくにあたって、たとえばある日急に精度が下がったとき、そのときの学習条件(ハイパーパラメータや入力データ)はなんだったのか等をすぐに簡単に確認できることはとても重要だと考えています。 また、これらの学習の途中経過や結果はより多くの関係者が気軽に確認できることが重要だと考えています。 そういった点で、SageMaker Experimentsを使ってきちんと実験管理を行い、QuickSightを使って可視化するというのは、取り組みやすく管理もしやすいと思っています。
AI推進部では引き続きこのようなML Opsに取り組む仲間を募集しています。 MLの持続可能な開発に興味がある方がいましたら、ぜひともご応募お待ちしております。
マネーフォワードでは、エンジニアを募集しています。 ご応募お待ちしています。
【サイトのご案内】 ■マネーフォワード採用サイト ■Wantedly ■京都開発拠点
【プロダクトのご紹介】 ■お金の見える化サービス 『マネーフォワード ME』 iPhone,iPad Android
■ビジネス向けバックオフィス向け業務効率化ソリューション 『マネーフォワード クラウド』
■だれでも貯まって増える お金の体質改善サービス 『マネーフォワード おかねせんせい』