
初カキコ…ども… 俺みたいなインターネットミームおじさん、他に、いますかっていねーか、はは 今日の社内の会話 あのシステムかっこいい とか あの機能ほしい とか ま、それが普通ですわな かたや俺は電子の砂漠でデッドロックしたレコードを見て、呟くんすわ it’a true wolrd.狂ってる?それ、誉め言葉ね。 好きなエディタ neovim 尊敬する人間 弊社CTO なんつってる間に4時っすよ(笑) あ~あ、会社員の辛いとこね、これ
というわけで初めましての方は初めまして、@ken11です。
最近はマネーフォワードのCTO室AI推進部という部署で、MLとかML Opsとかクソコラ職人とかやってます。
冒頭自己紹介がわりに古のコピペをぶっこんだけど大丈夫そ?
さて、そんなインターネットミームについて語る時間も欲しいところですが、今日はAI推進部らしくML学習パイプラインの話をしようと思います。
AWSにおけるML学習パイプラインの作成
いきなりですがAWSは好きですか? 僕は大好きです、AWS大好き芸人を自称しております。
そのAWSでMLモデルの継続トレーニングを考えたとき、まだまだベストプラクティスと呼べるものは存在しないのかなと感じます。 SageMakerが非常に多機能なんですが、多機能すぎていきなりだとなかなか全容を把握しきれなかったりするんですよね。どこから手をつけたらいいかすらわからなくて泣いちゃう。
でも実は個別の機能をうまく使っていくと、キレイなML学習パイプライン(※当社比)をつくることができるので、その流れを紹介したいと思います。
AWSのML学習パイプラインに悩めるみんな集まれ〜!
StepFunctions x SageMaker
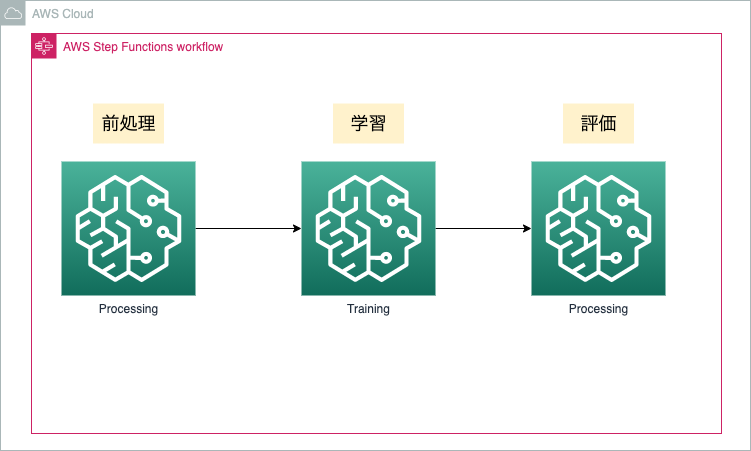
今回紹介するML学習パイプラインを図で表すとだいたいこんな感じ

いかがでしたか?みなさんも試してみてくださいね!
終 制作・著作 ━━━━━ ken11
嘘ですごめんなさい
さあいよいよ怒られそうだ
ここから真面目に解説するよ!
ProcessingとTrainingをStepFunctionsでつなげる
前述の図を見ていただくとだいたいわかるかとは思うんですが、基本的にSageMakerのProcessingの機能とTrainingの機能をStepFunctionsでつなげてパイプラインをつくります。 もう少しかみ砕くと
- Processingで前処理用のコンテナを起動して前処理を行う
- Trainingで学習用コンテナを起動して学習を行う
- Processingで評価用のコンテナを起動してモデルの評価を行う
- これらの流れをStepFunctionsでつなげて管理する
というのが、いま僕が実践しているAWSのML学習パイプラインです。
SageMakerのProcessingは誤解を恐れずに言うとインスタンスタイプを指定できるコンテナ利用のLambdaのような存在で、予め用意されているコンテナや自分で作ったコンテナイメージなどを使って好きな処理が実行できます。主にデータの前処理やモデルの評価で使います。 Trainingの方は文字通り学習用のサービスです。こちらはスポットインスタンスを使うこともできます。
ProcessingやTrainingの大きなメリットは、EC2のようにサーバ管理をする必要がないことです。簡単にMLモデルの学習を試す場合、GPU付きのEC2インスタンスを立てるというのはあるあるかと思いますが、長期的な運用を考えるとそれはなかなか手間もコストもかかる話だったりするので、SageMaker Trainingなどを使ってそういったストレスを回避するのは1つの手段です。
また、どちらもAWSのコンソールから利用できますが、Processingはなかなか気づかないサービスかもしれません。

入門用に、適切なroleを用意すれば一撃でパイプライン構築できるなにかをつくったので、ぜひ使ってみてください。
詳説
さらに踏み込んで解説させてもらうと、StepFunctionsとSageMakerにはPython用のSDKがあって、今回はこれを利用させてもらっています。
- https://sagemaker.readthedocs.io/en/stable/
- https://aws-step-functions-data-science-sdk.readthedocs.io/en/stable/
※これらのSDKを使った一連の流れを理解するにはこちらのノートブックがオススメです
このSDKを使うと ProcessingStep とか TrainingStep といったクラスを利用できるようになり、このクラスを使うことでSageMakerのProcessingやTrainingのステップをStepFunctionsに簡単に登録できるようになっています。
from stepfunctions.steps import Chain, ProcessingStep
from stepfunctions.workflow import Workflow
preprocess_step = ProcessingStep(
"Preprocessing step",
processor=preprocessor,
job_name="jobname",
inputs=[],
outputs=[],
container_entrypoint=[
"python3", "/opt/ml/processing/input/code/preprocess.py"
],
)
workflow_graph = Chain([preprocess_step])
branching_workflow = Workflow(
name="workflow",
definition=workflow_graph,
role="workflow_execution_role",
)
branching_workflow.create()
このような形で、Pythonを使って簡単にStepFunctionsを作れるのがこのSDKの魅力です。
では実際にStepで実行するProcessingやTraining自体はどうやって設定するのか?というと、 ProcessingStep は引数として processor というものを取るので、ここに ScriptProcessor などのSageMaker Python SDKにあるクラスを設定して渡してあげます。
https://github.com/ken11/ML-Workflow-with-SageMaker-and-StepFunctions/blob/master/workflow.py#L122-L130
このProcessor、いくつかフレームワーク用のものが事前に用意されているのですが、現場で使う頻度が多いのは自分でコンテナイメージを設定できる ScriptProcessor だと思います。
また、Trainingの方も同様の仕組みになっているのですが、 Trainer みたいなものは無くて、 Estimator を使うのでそこだけ注意が必要です。
これらのSDKのより具体的なコードは、上述のAWSさんのノートブックか、あるいは拙作のコードを読んでいただくとよりイメージが伝わるかもしれません。
Processing vs Lambda
ここまで読んで、Processingを使わずにLambdaでもいいんじゃない?と思った方もいるのではないでしょうか。自分も思いました。
気になったのでAWSさんに聞いてみたところ、用途と費用感にあわせて好きな方を使えばいいんじゃないかという回答でした。具体的に僕でもすぐわかる差分をあげると、CPUやGPUなどインスタンスの設定ができるのはProcessingのメリットだと思います。 前処理やモデルの評価で必ずしもGPUが必要になるわけではないですから、Lambdaの方がお手軽にできそうならそれでも十分だな〜とは思いました。
あ、言い忘れてましたがStepFunctionsはもちろんLambdaも使えるので、たとえば学習してモデルの評価まで終わった段階で、その評価内容をLambda使ってSlack通知みたいなこともかなり簡単にできてしまいます。 (まあ僕は自分でSlack用のKeras Callbackつくっちゃったからそれでもいいんだけど)
まとめ
こんな感じで、StepFunctionsとSageMaker、そのPythonSDKを使うと簡単にMLパイプライン作れちゃうよ〜っていう紹介でした。 AI推進部では日々このようなCI/CD/CTの効率化など、ML Opsに注力して活動しています。 もちろんモデルの研究・開発等も行ってますが、よりプロダクト実装に近い現場で、MLの持続可能な開発に興味がある方がいましたら、ぜひともご応募お待ちしております。
マネーフォワードでは、エンジニアを募集しています。 ご応募お待ちしています。
【サイトのご案内】 ■マネーフォワード採用サイト ■Wantedly ■京都開発拠点
【プロダクトのご紹介】 ■お金の見える化サービス 『マネーフォワード ME』 iPhone,iPad Android
■ビジネス向けバックオフィス向け業務効率化ソリューション 『マネーフォワード クラウド』
■だれでも貯まって増える お金の体質改善サービス 『マネーフォワード おかねせんせい』